In part 1, we will detail how we executed this decommissioning from a technical perspective, the reasons we had to decommission its use, and we will conclude with an explanation of how Crowd was used at both testing and production setups at SIG.
In part 2, we look at the new data model that was introduced, how data was effectively migrated between systems, and finally, we wrap up with a look at the performance and landscape benefits we gained from this effort.
There will be references to Amazon Cognito, which we use as our Single Sign-On cloud-based authentication provider. While we previously used Crowd for both authentication and authorization, as a result of this project the situation will be different: we are delegating our authentication to Amazon Cognito and authorization will be handled in a PostgreSQL database for which the schema can evolve more easily. The latter will be the focus of this blog series.
Introduction
Any software company that has been in business for a long time has had to deal with what are known as Large Scale Changes (LSC) at some point.
These changes can range from code only, staff and personnel changes, technology, or vision.
What all these changes have in common is that they require cross-team coordination (and even within a single team) over a fairly long period of time to ensure that they will land properly and without any outstanding issues or service degradation. The complexity of getting LSC to land properly is also affected by how the software being migrated is used in practice: it’s not a given that the consumer team will use the software being replaced as the developers who have created it intended.
Such a difference in usage introduces complexity where most time is usually spent, and can be a key driver in the decision to migrate away from the original solution once the complexity of such a custom usage outweighs the benefits of using the “right tool for the job”.
Let’s dive in.
The decommissioning from a technical perspective
We’ll first look at how this decommissioning was performed at a technical level.
At a high level, it required moving data from the source to be decommissioned to a newly introduced one, and, for a short period, to ensure both data sources were in sync.
This came with a number of challenges, and we’re not advocating this as the “One True Way” to perform this type of data migration, this is just how we approached it after considering the risks.
One of the biggest challenges in performing this decommissioning is that, since this involves authorization data for both SIG employees and customers, absolutely nothing was allowed to be broken or temporarily unavailable, as that could result in customers no longer being able to use any functionality whatsoever, which could negatively impact us and our customers’ businesses.
Additionally, besides ensuring that nothing would break, we also wanted to be able to continue delivering new functionality while working on this legacy decommissioning project.
To do this, we let the question: “How can we make it so that it doesn’t matter when exactly the data migration happens?” guide our efforts. One advantage of this approach is that it offered us the opportunity to onboard the members of our own platform team to use it and get familiar with the new set-up as early as possible. This ensured familiarity and a smooth transition, rather than only doing this at the end when everything was already set up.
This crucial aspect led us to follow “the safe road”.
In order to minimize risk, instead of performing a large-scale change (new code + data migration in lockstep) all at once, disabling the original data source (Atlassian Crowd), we applied the so-called “strangler architecture pattern”.
In addition to using this architecture pattern to ensure a smooth “service transition”, we also wanted to be able to work on this iteratively and validate small changes before moving on to the next one. Additionally, small changes have a small “blast radius” which makes the process safer.
This pattern also allowed us to shape our work in such a way that maximum parallelization was possible, which meant that different team members could work on dedicated services under the hood without running into each other’s work.
In our particular case, the strangler architecture pattern essentially allows Crowd and its replacement to coexist by abstracting access to downstream services behind what is known as a “strangler façade”: as we make the change, we keep both the old and new services side-by-side for some time, slowly migrating all dependent services to use the new one and phasing out the old one.
Finally, once all downstream services no longer use the old service, it can be removed from the codebase along with the strangler façade.
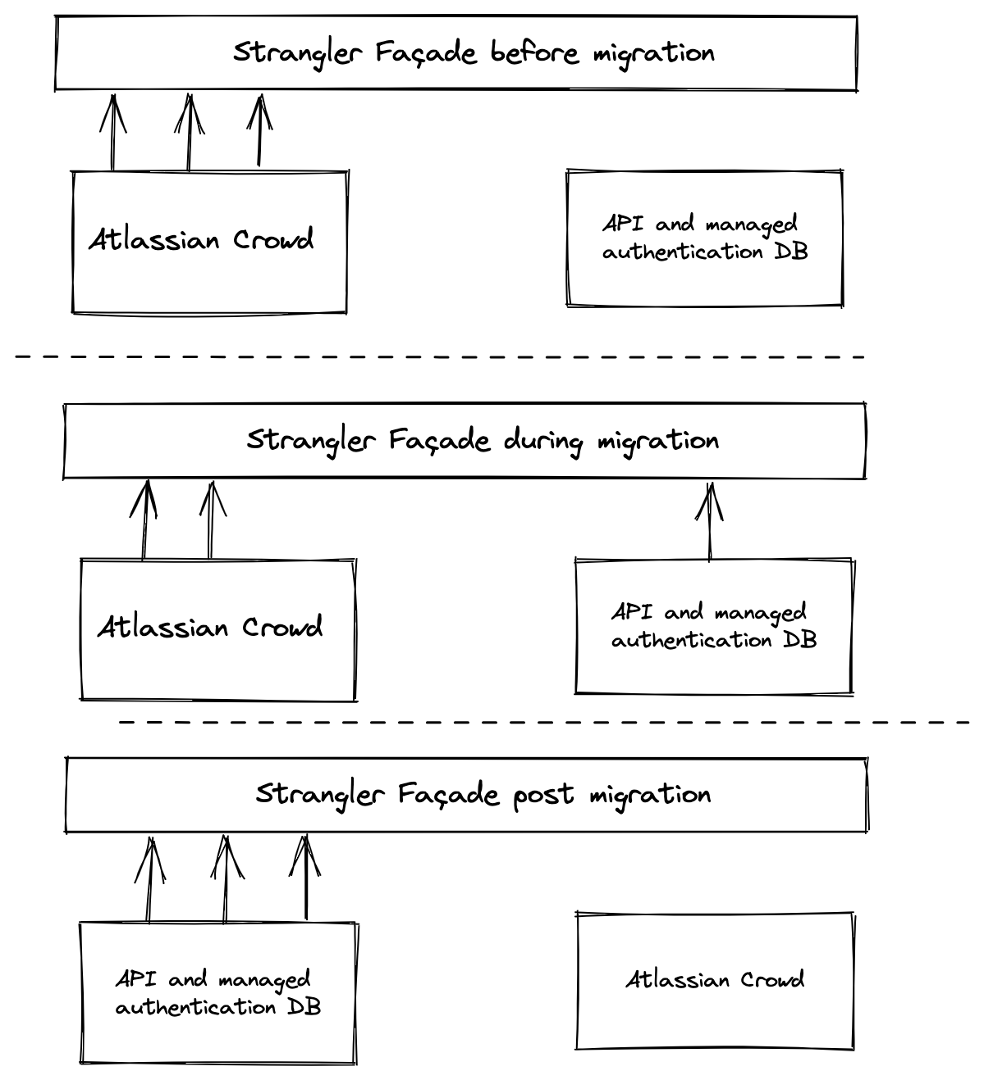
Figure 1 – The strangler architecture pattern
For our particular scenario, the way the “estrangement” manifested itself was through a one-to-one mapping between the conceptual models of the two services. Essentially, the concept of having the authorizations expressed by dedicated groups representing access to a given system was kept the same. (see the section on “How Crowd was used at SIG” for details)
So, while the actual data models between Crowd and our newly introduced API and DB were different, their underlying concepts remained the same.
While the migration was ongoing, groups were read from both Crowd and our new database for some time, and then all authorizations were “sanitized” by removing duplicates and ensuring consistency between both sources.
We also had an extensive set of tests covering this and preventing mistakes.
In this way, we were able to reliably carry out the migration unobtrusively “behind the scenes,” allowing our customers to keep using our platform without being aware of all the work that was happening in the background: this means that the strangler façade (enforced via data model compatibility and authorization sanitization from both sources) worked perfectly to protect downstream consumers from the effects of this change.
Reasons for decommissioning Crowd
There were several reasons for decommissioning Crowd, both business-related and technical, which we will briefly outline below:
- We wanted to allow some of our customers to use Single Sign-On to log into Sigrid. This means users can potentially use their own authentication system to log into Sigrid, which significantly improves the UX for our customers;
- We wanted to add Multi-Factor Authentication, as it is one of the most common methods for secure authentication today and prevalent in modern applications;
- In addition, clients began to ask for new custom authorization schemes that better suited their organization, and the Crowd-based solution did not provide the flexibility needed to implement and manage this as easily as we would have liked.
We were also not using Crowd in the way it was intended: we were using it to support Sigrid, which is an externally available application that uses multi-tenancy. Crowd was not meant for external exposure or multi-tenancy.
Due to these limitations, we decided to leverage Cognito to provide SSO for our customers.
By leveraging the functionality of Cognito’s identity pools, we support not only users managed in an existing user pool but also users who authenticate with external identity providers such as Facebook, Google, Apple, or an OIDC or SAML identity provider.
As an Amazon Web Services offering, Cognito was a natural fit for us, because much of our infrastructure was (and still is) managed by AWS, so, to stop depending on Crowd was a logical and natural next step.
Combined with the fact that our Crowd license was set to expire and was no longer an option for us, we found ourselves for a short period of time in a scenario where both Crowd and Amazon Cognito co-existed.
With the SSO setup and Crowd both in place to manage authentication and with Crowd also managing the authorization process, the complexity would grow to unmanageable levels.
With both mechanisms in play, the current stack would look like this:
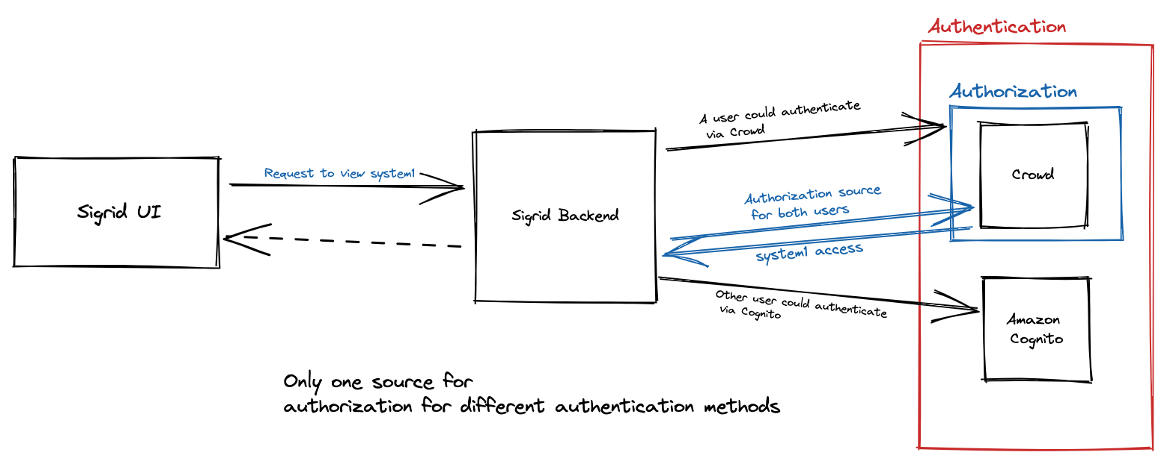
Figure 2 – The situation where both Crowd and Amazon Cognito for SSO coexisted
As can be seen above, this situation added a lot of extra complexity, and it would be very hard to manage and support going forward. Since Amazon Cognito is here to stay as the preferred way to offer SSO to our clients, having Crowd handle both flows would be extremely complex from a maintenance perspective, which was a good “goal to move away from”.
The other reason, shown in Figure 1, is that by taking Crowd out of the picture, we would gain a lot of ‘free performance’ because we didn’t have to make the round-trip to Crowd to retrieve authorizations on every request: with Crowd out of the picture, performance would automatically improve by replacing a component that was a bottleneck with one that is faster and over which we have full control. It’s also important to note that the Crowd round-trip would add about 3 to 4 seconds to every single request.
Now that we have detailed the decommissioning of Crowd from a technical perspective and outlined the reasons why we needed to do it, we’ll now show how we used Crowd at SIG.
How Crowd was used at SIG
External customers and employees have access to a single system or at a customer level, which can be considered a set of related systems.
So, as a general example, let’s assume we have a Portfolio, ‘sig’, which contains three systems 1, 2, and 3, which are systems representing specific parts of the internal SIG software landscape.
Out of these three systems, number 1 is considered critical, and as a consequence, not all developers can access it, let’s say, only admin users have access.
The way we used Crowd to manage authorizations is as follows:
Crowd has the top-level concept of a directory that contains authentication and authorization information about users and groups. Crowd supports an unlimited number of directories. Administrators can use different directories to create silos of users.
The directory is associated with an application and the relevant groups get created in the specified directory. In the generic example above, the groups would be:
‘sig-system1’, ‘sig-system2’, and ‘sig-system3’.
These would represent authorizations for systems ‘system1’, ‘system2’, and ‘system3’ of ‘sig’.
In terms of integration with our codebase, the use of Crowd predominated, both in our production and testing setup.
Crowd as part of our production setup
The basic flow when a request reaches our back-end is a combination of responsibilities between the Spring Security filter chain and Crowd to decide whether a user is authorized to access a specific resource.
In our chain is a dedicated filter whose sole purpose is to contact Crowd to retrieve what is defined as a “list of groups”. These groups encode the authorizations for a particular user and will determine whether access is granted.
The diagram below provides a high-level overview of our production setup.
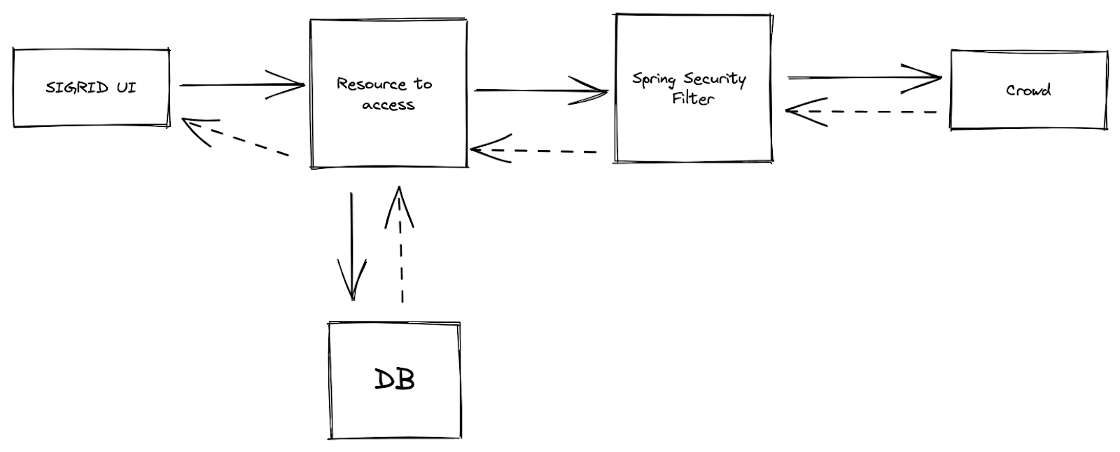
Figure 3 – Simplified setup of how Crowd fits in our production setup
An important detail is that when using a user’s information to contact Crowd, the group sets will be scoped by a combination of user details and the portfolio for which access is requested: SIG employees are located within a specific Crowd application that could be called “SIG”. Within this directory, we would have the relevant permissions to individual portfolios and within each portfolio, there would be several systems with a list of users who are allowed access to them.
Continuing with the above example, I would not be placed within the group “sig-system1” because I would not have access to it.
As a result, the Crowd call would not grant me access to that system, and I would not be able to access it.
This is how our production setup is done at a very high level. Let’s look at the impact of Crowd on testing.
Crowd as part of our test setup
In addition to the production setup, to test and validate the correct access to our endpoints by different customers, as well as validate how the UI configuration and messages would look, we needed a way to embed Crowd into our integration tests to ensure that access control was kept as intended when adding new endpoints and/or modifying existing ones.
As discussed in our previous article about how we do CI/CD at SIG, we use Docker to isolate and easily leverage our dependencies in different environments, such as the dedicated back-end or front-end integration testing.
As part of our test setup, a very bare-bones Crowd server was emulated and exposed to our test environment via a dockerized Mountebank setup.
The basic idea is to simulate the possible combinations of authorizations for a specific set of test systems that can be used to validate both the correct authorization enforcement and the actual underlying implementation for different types of users. An external user should not have access to internal SIG systems, while a special test user can have broader access as it is only used within the context of these integration tests, for example.
The way we found to encode these different permissions is shown below:
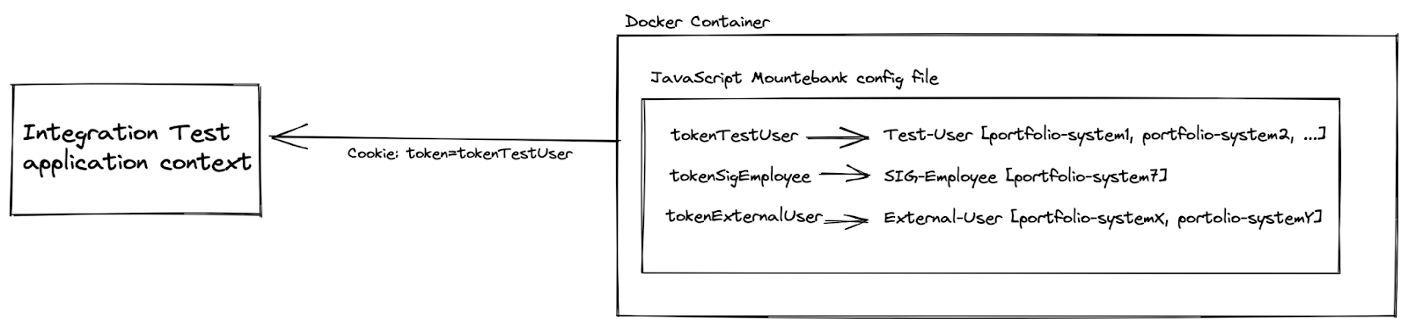
Figure 4 – How we mocked and used Crowd in our testing setup.
To conclude, there may be differences in the JS mountebank configuration files between the back-end and front-end for different testing scenarios. The front-end needs to be much more thorough with permissions to validate rendering of, for example, error messages, pop-ups, and other things, while the back-end is, strictly speaking, only interested in a particular response code and/or body depending on the type of API endpoints being implemented.
Conclusion
In this first post on legacy modernization at SIG, we looked at how we performed the decommissioning of Atlassian Crowd from a technical point of view, outlining together with it, the technical and business-related reasons to do so.
Then we also briefly looked at how we were using it at SIG to give some additional context to the actual decommissioning.
In the next blog post, we will look at the newly introduced data model that was used to support the migration, we will look at exactly how the migration of the data was done, and, lastly, we will look at some benchmarks that detail the performance gains we have achieved.