At SIG, following the industry best practices that we recommend to our customers is something we find very important, because it embodies the values that we consider important for crafting high-quality software and it shows that we care about and follow our own recommendations.
One of those best practices is the robustness of the test setups for soon-to-be production code, i.e. code that will be merged into production needs to be thoroughly tested at several different levels: unit, integration, and end-to-end.
Thanks to the complexity of modern software development, from both a code and tooling perspective as well as the complexity of the domains for which code is being written to solve business problems, a new aspect of testing is gaining traction. I personally like to name it branch testing.
The idea behind branch testing is to create an ephemeral, throw-away environment that spins up a copy of the production application being served to clients. The main difference is the code that’s being deployed is not the latest or production, but instead a branch containing a new feature, a bug fix, a performance improvement or anything else that we are interested in validating before deploying to production.
We’ll show how we work with these on-demand environments and how we do branch deployments at SIG.
On-demand environments at SIG
Having and using on-demand environments has been enabled in modern workflows thanks to Docker and Kubernetes. They make it easy to create isolated packages of everything our application requires to run in isolation. The docker images will bundle all our code and its associated dependencies. Leveraging a Kubernetes cluster, we can deploy those docker images containing our containerized code and run it in such a way that we can expose it to our company’s internal network, effectively generating an accessible URL where our entire application gets deployed and is available for testing by our colleagues.
The database used as the base for this deployment is a production replica – essentially a throw-away copy of our entire production database via a backup done with AWS. The idea behind these “on-demand environments” is to hook up this database replica into our containerized setup. Once we start our application from our Kubernetes cluster, we’ll be running a full copy of our production application codewise. The provisioned infrastructure will differ since this will be our Kubernetes cluster which we manage with EKS, not our production setup.
Configuring on-demand environments at SIG
The way we configure “on-demand environments” at SIG consists of applying a Kubernetes deployment to an already provisioned EKS cluster following a semi-automated process.
When creating an on-demand deployment, the only requirements are:
- the branch name containing the code to deploy,
- the credentials and URL of the database replica from AWS, and
- a defined set of values (usually the ones corresponding to the current production deployment) for all other services needed to spin up our complete application.
All of these values are added in a `deployment.properties` file that is added to your repository gitignore file so it doesn’t end up in version control. The reason is that this file is dynamically generated with every new deployment we make.
Once that’s done, we run the `mvn deploy` command which will create the Kubernetes deployment Yaml file programmatically using the `cdk8s` library.
This enables developers to define in code (in the programming languages they are most familiar with like Typescript, JavaScript, Python, Java, and Go) all the necessary Kubernetes resources, like Services, Deployment, Ingresses, etc. All without the need to write Yaml files manually. It’s like an extension of your day-to-day programming language that allows you to define Kubernetes deployments without requiring you to manage YAML files manually.
For many developers who are not familiar with infrastructure-as-code, writing YAML files manually to configure all the services that will be running on the cluster is error-prone, and time-consuming.
For the use case of having on-demand environments readily available to be used, a helm chart is not necessary since these environments are very short-lived and essentially ephemeral, avoiding the need for managing them with Helm.
Afterwards, the deployment can be applied to the cluster by running the `mvn deploy` goal as cdk8s hooks into Maven’s deployment plugin.
This command will execute the programmatically-specified deployment against the cluster, which will, in our particular case, create a new namespace and provision and spin up all the associated resources in that namespace needed to start our “on-demand” application.
Using Kubernetes namespaces, we can ensure that multiple developers can spin up several application instances without conflicting with each other since these user-defined namespaces isolate resources within the cluster. As a development team, this enables us to test significant changes “in production” and in parallel without any bottlenecks, which are very valuable because they allow us to move fast and with confidence in our work.
When we finish testing our changes, we can just run `kubectl delete -f <name_of_yaml_file>.yml` to remove associated resources from the cluster freeing up resources for other developers!
Using cdk8s to configure a Kubernetes deployment with code
To use cdk8s in your project, make sure to add the necessary maven dependencies to your project so that the library is picked up correctly in your project. Once that’s done, you can follow the example on the setup page on the official website and get started from there.
At SIG, we use a custom setup on top of the existing functionality provided by the library, which allows us to configure our services in a declarative way.
We have a configuration class, `Configuration`, that reads all the property values from the property file mentioned above and loads them into Java to link them together at runtime to create our Kubernetes Yaml file.
Besides this class, we define an abstract class, called `WebService` defined as follows:
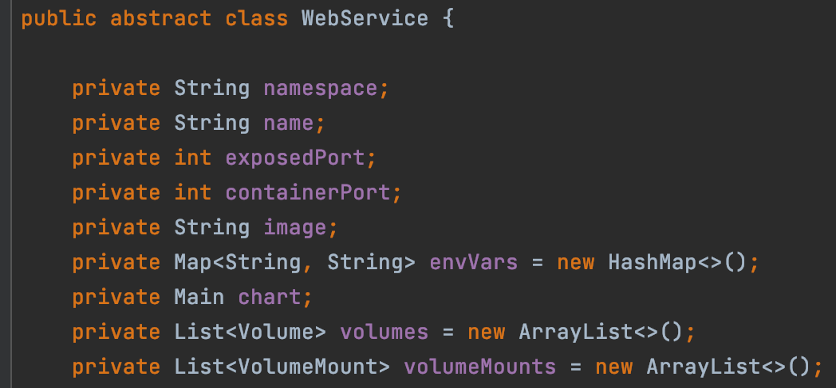
We use this base class to define our specific service details in code by extending from it. The details for the name, image, ports, and environment variables are all service-specific.
However, it’s very important to notice that the namespace value and the cdk8s Charts are globally defined per deployment.
A cdk8s Chart is a base class from the library that serves as a container class for all the services that will form our final complete deployment in code. We define the Main class which contains the definitions of all the services that we want to provision in our cluster.
After that, we define an App instance, which we call the `synth` command, and will generate the final Kubernetes deployment Yaml file from this code specification. Note that the `synth` command is specific from the ck8s library, but we can also generate this deployment file by running the `mvn package` goal.
By leveraging the tight integration between cdk8s and maven’s deployment plugin, we can generate the Kubernetes deployment specification by running a maven command which is very similar to existing workflows, making it easy for new developers to be up to speed with this process.
Observability and usability of our implementation of “on-demand environments”
One of the biggest challenges that teams face when adopting custom solutions, like the one we described here for creating on-demand environments, is that everything feels very barebone. There are some rough edges for usability and accessibility that are fine for experimentation while our solution is gaining traction. However, it can be harmful to bringing new developers into the fold in the long run.
Fortunately, setting up simple tools to improve the user experience and increase observability is relatively easy within the Kubernetes ecosystem, and we will look at three tools here.
1. Capability of auto-completion for Kubernetes commands
The first one is the capability of auto-completion for Kubernetes commands. As an example, when typing `kubectl get p` and then hitting Tab, we would be able to see the following listing:

This can be especially useful for listing namespaces or seeing resources at a glance when the setup starts growing.
To set this up, we can leverage an official script available here, where we have detailed instructions on setting up this script on our preferred shell environment to be provided with these very useful auto-complete capabilities.
Once you configure your shell by editing its corresponding configuration file (e.g. bashrc or zshrc, for bash or zsh, respectively) and restart your terminal, you will have the Kubernetes commands auto-completion enabled. It’s a low-effort, high-gain solution that we definitely can recommend.
2. K9s
The second tool is called k9s, and this is a fantastic tool for cluster management and observability that significantly improves the overall Kubernetes experience. In order to configure it, some extra work is required, but it is well worth the extra effort.
You can follow the installation instructions for the tool here, and once you run the command `k9s`, in your terminal, you will be presented with:
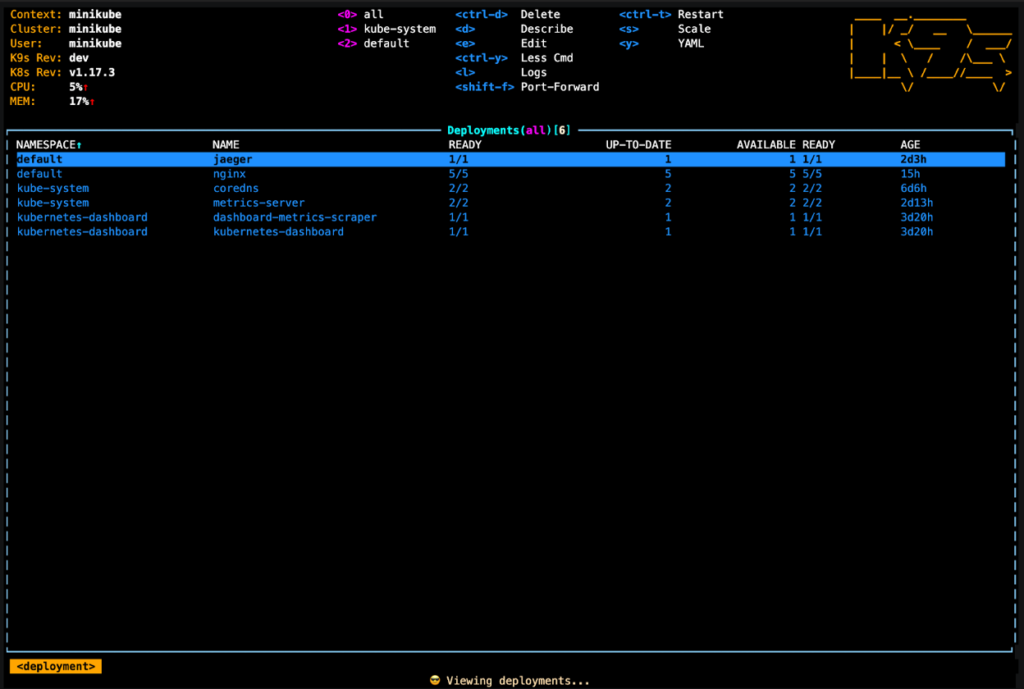
From this top-level dashboard view, you can see different deployments, namespaces, check for logs, filter out information you need with regex, and even look into the YAML description of your cluster objects.
It makes it a lot easier to grep for logs and look at a glance into the several namespaces currently available in the cluster, which can be great to align with colleagues and ensure that cluster management is in reach for everyone using the cluster.
Furthermore, logs can be configured to be seen at specific intervals. Capabilities like auto-scrolling, searching, and much more are a nice upgrade over the more native experience of interacting with the cluster solely via the kubectl command.
It’s a very useful tool to check if you are using Kubernetes clusters or planning to do so.
3. IDEs
And last but not least, we can actually rely on our own IDEs when it comes to supporting Kubernetes integration. IntelliJ IDEA has a plugin for Kubernetes that can be installed and gives you access to a lot of what we have covered here, all while staying within the comfort of your own IDE.
After installing the plugin for Kubernetes, IntelliJ will automatically detect any cluster configuration you have in your local machine, (for example via the `.kubeconfig` file) and the context for that particular cluster will be available from within the `Services` tab in the IDE:
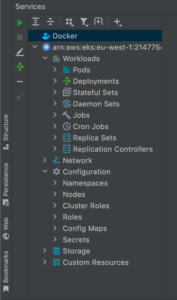
Here we can see the status of the cluster we are currently working with, and under the `Workloads` tab we can see our resources like Pods, Deployments, Jobs, etc.
This facilitates the management of our cluster as well as its overview because all our resources are within one single place, which is a lot easier to manage!
Finally, a worthy note to wrap it up. There are context menus available at right-click for most of these resources and they allow us to see logs, follow them, see namespaces, and more:
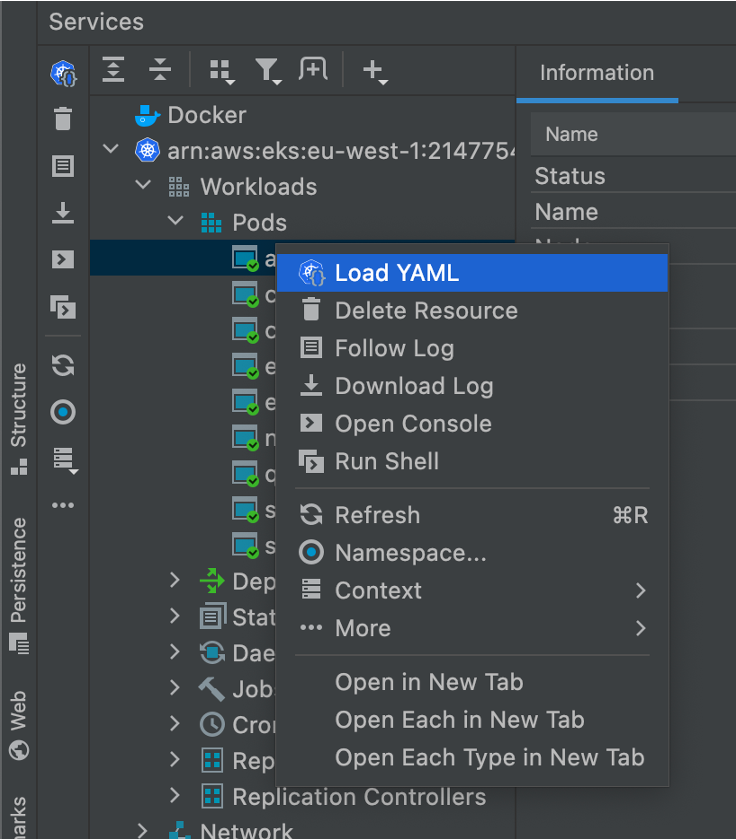
With these context menus at your disposal, you can actually switch namespaces, tail logs, and remove resources using the IDE directly which is a great way to have an overview of the state of your cluster while manipulating it with familiar tools.
Conclusion
Hopefully, after reading about our own experience about how we leverage Kubernetes to provide our developers with an “on-demand production environment”, you are now also sold on its usefulness, are willing to experiment with it and come up with novel approaches to set up your own environments to enable your teams to move faster more confidently.
At SIG, we are always experimenting with new technologies and are actively maturing our Kubernetes ecosystem.
While the road is bumpy, if you and your developers invest in it, it is possible to create custom solutions to fit your development workflows and company culture to leverage Kubernetes to empower your developers to work on new features with more confidence and move faster.
Note: Special thanks to my colleague Fabian Lockhorst for the review of the blog post while it was being written and for the insightful comments to complete the section about the observability of Kubernetes clusters for our on-demand environments.