In modern software development, the only constant is change: business needs evolve over time, features are added, expanded or removed accordingly, and development teams doing the work themselves are also subject to change over time. All this makes the whole software development process more complex and uncertain.
As such, it is becoming increasingly important for software development teams to find ways to manage complexity and ensure that both current and future development work is done while taking into account all the decisions that have been made before.
By doing so, all the changes that have happened over time can be leveraged today, so that better decisions can be made tomorrow.
One of the ways that the SIG development team found effective in enabling better decision-making is the use of Architecture Decision Records – ADRs, for short.
We will look at what an ADR is, as a general concept, as it’s not really new nor unique to SIG, and then we will detail how we “implement it” in practice for our specific context.
What is an ADR, and why use it?
As discussed above, any production-grade software product will always be backed by a shifting landscape behind the scenes: changes in business requirements, changes to the teams that write and maintain the software, and external changes, like new framework and language versions that open up many possibilities and deprecate others.
With so many changes, it can become impossible for a team to keep track of everything taking place in all the different areas that make up a software product.
As a result, something needs to be introduced within the team’s development process that allows teams to manage all this inherent complexity in a way that is effective, has low overhead, and can actually be kept somewhere.
In this way, it can be consulted when needed or desired, and can be tracked over time. Ideally, kept in version control so that it can evolve and “sit next” to the actual code, where architectural decisions will more likely be materialized, why?
Because architectural decisions are usually made taking the current software architecture into account. When code changes, and we want to document how and why it needed to change, it’s only logical to keep these close together.
By keeping this decision-making process in version control next to the code, we benefit from locality and visibility. It turns out that such a standardized way of doing this already exists and is in practice described and used by the software engineering community formally called an “Architecture Decision Record”.
Looking at ThoughtWorks’s nice description on their Technology Radar on this exact topic, we can describe a “lightweight” version of an Architecture Decision Record as a technique for capturing important decisions with their context and consequences.
The structure of an ADR can vary depending on various aspects, such as your specific goals when using it, the level of maturity of the team that wants to implement it, etc., but as a general structure, the image below is a good starting point:
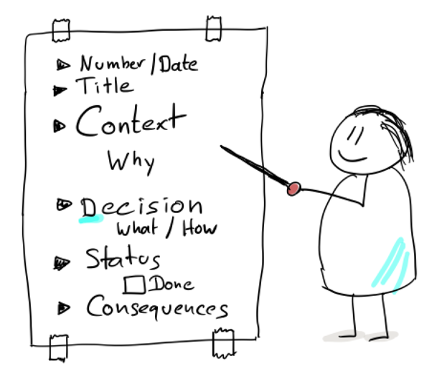
Figure 1 – Example structure of a lightweight ADR (Source: RedHat)
Let’s quickly dissect the above structure and look at the usefulness of each field and how they, as a whole, provide a cohesive view of all the significant architectural decisions made during the life of a project. Let’s take a look at how to structure an ADR for a particular example.
Small case study: at a certain point in time, it was decided that a specific DB table T would not be queried directly anymore in favour of using a service S which proved to be more reliable and easier to test.
Based on the above case study, let’s see what an ADR would look like:
- Identifier/Date: both the identifier and the date are very significant. The identifier (which can be as simple as a number) can serve as the means to sort the various records in a logical order when viewed simply as a list of decisions. The date is useful to have a way to “anchor” in time when a particular architectural decision was introduced into a system.
E.g.: “1. (21-02-2023) …”
This makes it easier to look back in time and identify key moments of the project’s evolution, which is useful for both new joiners and more experienced members of a team to have a good overview of how the system evolved.
- Title: self-explanatory. A title is usually tied to some business or technical decision that was worth capturing, and people familiar with the domain should immediately derive the necessary context from the title.
E.g. “Direct table T query deprecation in favor of usage of service S”
- Context: the context provided about why this architectural decision was made. This section explains the factors that led to the decision. These can be technical factors, for example a vulnerability in a key library was discovered, and now a change is required to cope with it, or the business introduces requirements that disrupt existing architecture, etc.
E.g. “Due to reliability issues and a hard time testing the business logic when we query a DB table directly, since correctness via testing and encapsulation via services is preferred, we have decided to introduce a new service to handle this piece of business logic.”
- Decision: the actual decision. This section is the “meat on the bone” of an ADR, and it describes in detail what has changed and how the change was materialized in the domain, be it through code, documentation or a new process being introduced, but either way, all of that is described here.
E.g. “A new service will be introduced in package x.y.z which will encapsulate the logic that was covered by the old direct DB query. The service must rely on using Hibernate to abstract the low-level details as much as possible to gain future flexibility when working on this area of the codebase.”
- Status: the status of the ADR is used to indicate to who will read the document in the future whether the decision is “effective”, as in approved, validated and in use, or whether it’s under review, abandoned, etc. There is no standard for the statuses used, as long as they clearly and unambiguously indicate the usage of the decision in practice.
E.g. “Status: Approved”
- Consequences: the consequences describe the current state of the system after the ADR comes into effect. This section indicates how the system has changed and how the new set of changes will affect people working on the system from that point onwards. Documenting these consequences gives us a good overview of the evolution of the system and how it is shaping up as business requirements demand, and it can be an invaluable resource for processes like onboarding new people and getting them up to speed quickly.
E.g. “No longer query table T, instead use service S which will be the standard operating procedure from now on.”
While not all lightweight ADRs have to follow this exact structure, these sections are usually present in an ADR. They provide a great overview of the tandem between software and the business itself while being extremely valuable as a resource for sharing knowledge, upskilling the entire team, and onboarding new people.
How we use ADRs at SIG
Now that we’ve looked at ADRs in general and how they can bring several benefits to a software development team, let’s look at how an ADR is written in practice at SIG.
There can be many ways to materialize an ADR, but for our use, and since we use lightweight ADRs, we decided to take the simplest approach that works.
At the top level of our backend repository, we have a docs folder, and one level down we have another folder named architecture_decision_record. By having it as a folder in our top-level repository, we immediately take advantage of the benefits of version control, so every change we make to our ADRs is documented in our version control systems, which is a great advantage for traceability and history.
Each individual ADR is created as a Markdown document that follows a specific template that is very similar to the one shown above: the convention when naming a newly created markdown file is the format: XXX – <a descriptive title highlighting the decision> where XXX is a number so all the decisions can be ordered, and the title very generically describes the purpose and content of the document.
As for the structure of the document itself, it contains six main sections that we leverage, many of which overlap with what is described above: date, status, context, decision and consequences.
The SIG template we use also includes an additional field called “Other options considered”. As the name implies, this is a dedicated section of an ADR where we look at different options that we have considered before making a final decision. The value of this section is that we become broader and more open-minded in terms of what is possible within our tech stack, what we can do or cannot do, and it’s also a way to stretch the limits of our own codebase, where sometimes performance improvements or optimizations can be hiding “in plain sight”.
Conclusion
We hope this blog showed you the value of adopting ADRs within your own software projects and teams. It is a simple, low-overhead way of documenting architectural decisions that offer many additional benefits, like traceability of decisions over time, trade-offs, and how the codebase and business change over time, and serves as a historical record of a project’s life cycle. By adopting it, you also help newcomers to the team immediately gain context that might otherwise be lost by being considered “institutional knowledge”. Making these decisions visible will increase team and project resilience over time and make it easier to make better and more well-informed decisions to guide the projects and teams to their maximum potential.