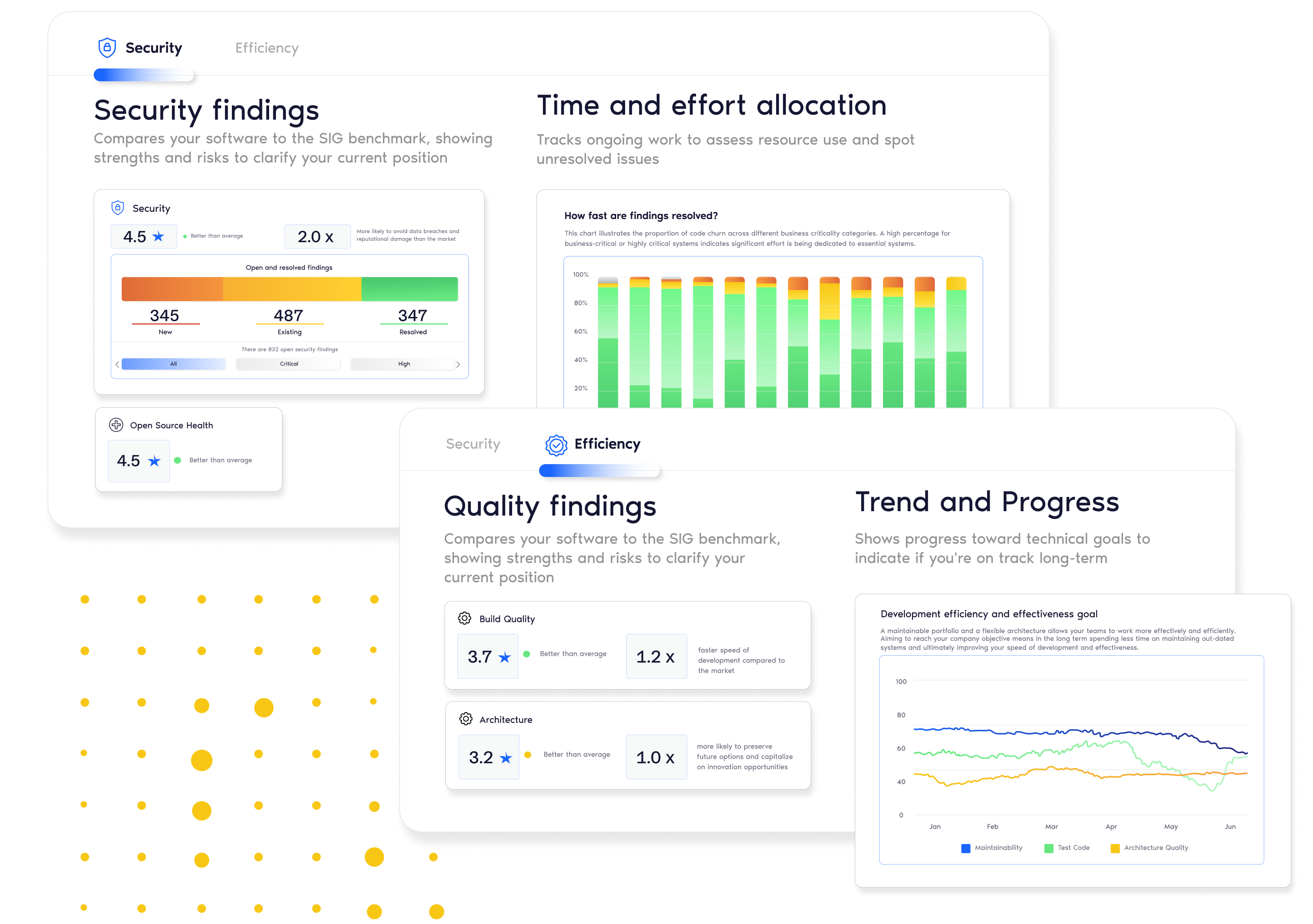
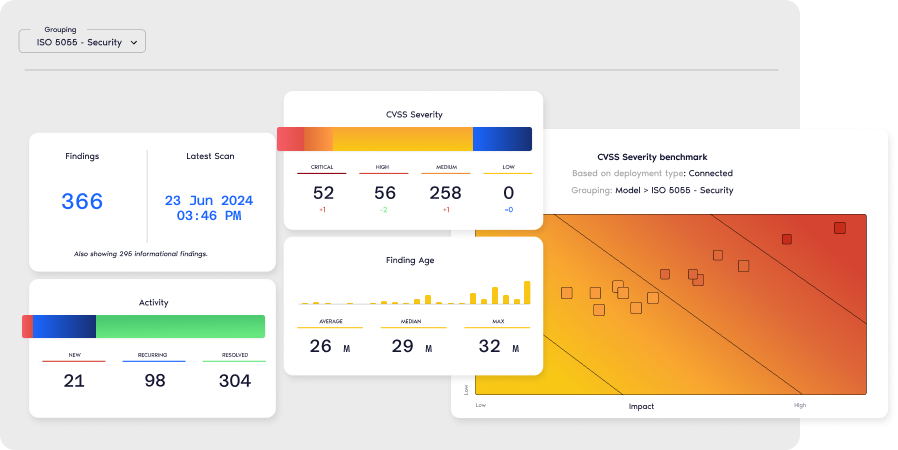
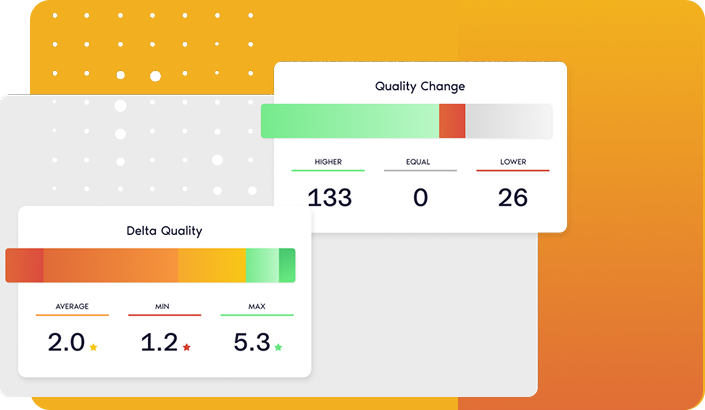
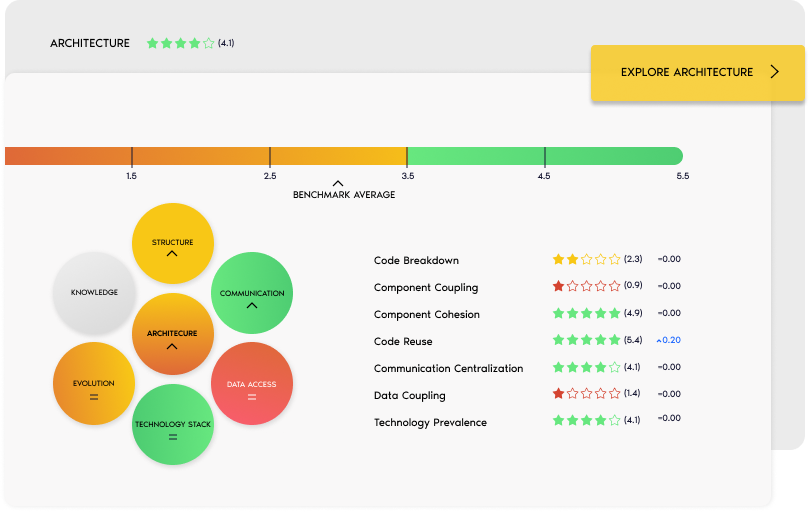
Management Dashboard
Translate technical findings into clear business KPIs so that you can simplify IT-business alignment.





“Tooling like Sigrid provides transparency, allowing us to manage our software proactively and maintain high standards. This is crucial for securely sharing personal data in our digital processes and staying ahead of potential security risks.”
“With the help of Software Improvement Group, and their platform Sigrid, we can invest more effectively in code quality improvement and development."

Software Improvement Group helps us access and interpret the data so that we can improve things better and more quickly."
“We chose Sigrid to validate the strength of our code base, ensuring our foundations are as robust as we believe. This allowed us to focus our investments on targeted improvements and bolster our security, turning insight into action for a safer, stronger product.”
“We needed an independent partner to help us measure the systems. They can tell us that everything is perfectly fine, but we needed to know for sure. With Sigrid®, we’re getting more guarantees that the software that’s being delivered is up to par.”
