AI technology is becoming mainstream, quickly moving beyond the thriving AI startup ecosystem. Even traditional organizations, such as banks, insurance companies, and manufacturers are starting to implement AI as part of their core software.
According to McKinsey, 88% of of organizations report using AI technology in at least one business function.
Often, we see that organizations want to integrate with their existing (BI) data infrastructure and leverage their available software expertise as much as possible.
Their management often worries whether the right practices are in place to ensure trustworthy outcomes that will outperform their existing solutions.
How can they know if their AI teams are applying current best practices and heading in the right direction? Do they have the right software expertise to apply engineering best practices? Do their processes adequately deal with fundamental challenges such as explainability and fairness?
At Software Improvement Group, we help organizations move faster, responsibly.
Clients sometimes struggle with aging legacy software full of outdated design and technology; or they wonder how to prevent the same mistakes when starting anew; or they want to benefit from experimental technology, such as AI, but would prefer to have some assurance.
We typically apply a spectrum of instruments to drive our consulting at each particular client; including automatic software quality measurement, open-source (library) health scans, architecture & security analyses, and assessments of development practices.
While we’ve recently updated most of our instruments to consider AI directly, in this article, we focus on AI engineering practices.
Recently, various sources have begun describing best practices for (parts of) the AI engineering process, such as Microsoft1 and Google2, followed by academic research activity, such as the week-long retreat, “SE4ML – Software Engineering for AI-ML-based Systems? in 2020 at Schloss Daghstul3, and the catalog of software engineering practices for machine learning (SE-ML) initiative by Leiden University in the Netherlands4. To kick start our efforts to build an AI Practices Assessment (AIPA) instrument, we combined such sources with the experiences collected by our own AI practice group at SIG.
In this article, my colleague, Rob van der Veer, and I discuss AI engineering practices and relevant tips and tricks with the team at Kepler Vision Technologies.
Kepler is an Amsterdam-based company providing computer vision and deep learning technology for the health care industry. Its flagship product, the Kepler Night Nurse, assists caregivers by identifying relevant events in video streams, such as an elderly person struggling to get out of bed or falling down.
Kepler Vision Technologies is at the forefront of engineering deep learning pipelines, staying firmly rooted in modern-day software development practices. Their software engineers, Per John and Rob van der Leek, have long been active in the software quality assurance business as both engineers and consultants. Their expertise in software engineering has allowed the company to automate most steps of the AI process, leading to advantages in repeatability, error correction, and speed. In his 2019 blog for Towards Data Science, John outlined their key software development practices for deep learning.
AI engineering practices
Our conversation below with John and van der Leek touches on some of the most important AI practices being applied at Kepler Vision Technologies as well as the improvement points their team sees. We loosely follow the AI engineering map pictured below, discussing data and model engineering, regular software engineering, and finally, AI operations and governance.
Note: this image is a generic representation of the AI engineering processes as we have observed them in the wild. John and van der Leek suggest that for AI that is mostly used for computer vision, data preparation can require relatively less code and effort than depicted here.
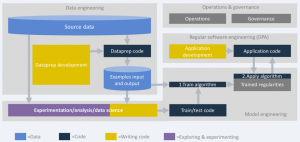
Practices in data, model, and software engineering, and in operations and governance of AI projects.
Data engineering
Data engineering is about making sense of the source data and getting it in shape for the next steps. In this pivotal and laborious activity (some sources mention up to 80% of overall effort5), raw and unclean source data are filtered, transformed and cleaned, resulting in usable examples for the next steps in the AI pipeline. What data engineering practices are considered essential in academic and trade literature, and how are they applied at Kepler Vision Technologies?
Ensuring data provenance and feature ownership
Magiel Bruntink and Rob van der Veer, Software Improvement Group (SIG): Data constitute the starting point of any AI project, whatever algorithm they apply. Many sources state that it’s essential to keep track of the origin of data sets for several purposes: compliance, recovery, and good old engineering practice. A data set needs to be provided with metadata that clarify provenance, i.e., where, how, when, and by whom the data was collected. Also, if there have been any changes to the data since collection, those need to be recorded as well.
Per John and Rob van der Leek, Kepler Vision Technologies (KVT): Our data are primarily video frames, i.e. images, produced by cameras installed at clients of our Night Nurse product. The images are stored on a (cloud-hosted) file system that has a carefully-designed directory structure to facilitate provenance tracking. This structure allows us to, for instance, delete data upon a client’s request, or to refer to a particular data set when training models. The images themselves are not tracked using version control, as updates to individual images are very rare. However, we also have so-called annotations on the images, which our annotation staff produces to label relevant activities in an image (e.g., a person sitting down, or lying on the floor). These annotations are kept as separate text files in a version control system.
SIG: Data sets can be very similar to source code in the sense that they require specific knowledge and maintenance to remain valuable, particularly if they include specifically-engineered features. Those also require specific knowledge to maintain, calling for a clear ownership. How do you tackle the risk that people might leave your organization, leading to a loss of knowledge?
KVT: Since our data sets are generally low on complexity, we don’t see this as a big risk for us. Although we do have a dedicated person on the modeling team that keeps track of the data features we created, using low techs methods such as a spreadsheet or document.
Automating data cleaning and transformation
SIG: Data are often reflections of real-life processes and, hence, errors and misrepresentations. Many AI projects therefore include explicit activities where data are cleaned, scrubbed, massaged, pre-processed, and transformed. The best practice here is to automate such data preparation steps, as suggested by many sources 245678. What can you share about your practice?
KVT: Our training and testing data sets are collected very carefully in the field. Our staff go out to our client locations specifically to collect good training and testing examples. These data are then annotated by specifically-trained staff. No additional automated cleaning steps are needed on those data. In our processing pipeline, example images are then normalized automatically to be ready for training or testing. In addition, we obtain examples for our training and testing sets by running our existing models on images we collected in operations or from external sources. If our models provide surprising outcomes for such images, we manually inspect them to see if they are good candidates for inclusion. All in all, our data collection process is curated mostly by human effort, supported by automation for basic processing steps.
SIG: Since you automate at least part of your data preparation pipeline, do you apply typical programming best practices?
KVT: Yes, we treat data preparation code like any other code base. It needs code quality checking and unit testing, for example.
Centralizing data storage and access control
SIG: In general, most members of an AI team need frequent access to its (training and testing) data sets. Without easy access to the latest data, the modeling effort will suffer from data becoming out-of-date or inaccurately representing the problem to some extent. Without centralized storage, another risk is that team members may start working with data copies, maybe even modified for their own purposes. How have you organized your data infrastructure?
KVT: All of our data sets are stored centrally on a cloud service, with all the necessary security measures in place. What is working out very well is an on-demand synchronization mechanism for data sets. In the case that a model needs training data, for instance, a specific (cloud-hosted) machine is set up for that task, the required data is copied to that machine, the task is executed, and afterwards, the machine is taken down again. That way, data copies are never kept around.
SIG: If the data can identify people, how do you deal with the necessary compliance controls to meet standards demanded by GDPR, such as personal data protection, encryption, access control, and so on?
KVT: GDPR compliance is a necessary and non-trivial aspect of applying AI to personal data. Obviously, you need to, for instance, be able to delete a client’s data upon their request. So you need to treat your data provenance seriously, as we have already discussed. More broadly, to show compliance, you need to document how you comply with relevant standards such as ISO/IEC 27001 (Information Security Management). Then, we need to coordinate the consent of various parties, such as the compliance officer and our clients, before we are even allowed to store their data. It’s easy to underestimate the amount of time you need to invest in these necessary steps.
SIG: Is there any impact on your models if you are required to delete a client’s data?
KVT: Yes, if we keep the models trained in part on data we are asked to delete, the performance of these models may suffer in future training steps.
Model Engineering
Modeling is often an experimental process, where dozens of model configurations are attempted before a model version is chosen for further evaluation. Models are almost always described using code or configuration text to set the model’s (hyper) parameters, and in the case of deep learning models, their layers and topology. Down the line, a model will be trained, further evaluated for performance, and possibly deployed to production. In total, the model’s lifetime can be days to weeks to even months.
Ensuring model traceability using central storage and versioning
SIG: There will always be plenty of reasons why a team will want to reflect back to the code that created the model they are currently working with, in the case of issues or requests for improvements of performance. A key practice is therefore to record model configuration code in central version control and ensure that proper tagging is done for model versions that proceed to training and further. To what extent do you implement such practices?
KVT: Version control systems are useful to track changes on source files that people maintain. We put our model configurations, e.g. the code creating neural network topologies, in version control. However, other scripting that e.g. sets hyper parameters for model training, are archived but not kept versioned. Then, the results of model training, which can be rather large files containing network weights, are tagged and archived, but not kept under version control due to their large size, and little benefit in doing so. We also make sure that a trained model has a tag that connects them back to their training data.
Automating the modeling process
SIG: Model training and evaluation are the equivalent of compiling a codebase for testing and/or release. It will happen frequently and continuously, both when an AI team is still looking to create its initial models, or when it’s maintaining currently operational models. Can you tell us to what extent you were able to automate your modeling pipeline?
KVT: We created a fully automated pipeline using Jenkins, the well-known open source automation server. Basically, you only need to point to the model configuration and the training data, and it can take everything from there. This setup makes the modeling process way more predictable, fast, and standardized.
Ensuring model quality with continuous testing
SIG: Learning models are meant to solve a task, such as classification or prediction. Given this task, it’s often clear that performance of the models can be tested against the known data sets. Preferably, the testing data also originates from a different source than the training data. That’s all elementary stuff, but how does that work in practice for you?
KVT: An elementary practice is to partition data sets into training and testing data and use the latter category only for testing and validation purposes. Many of our models have a generic base, which was trained and tested with well-known data sets for object recognition in images. Then, we further train those models with data we specifically collected from our clients. Naturally, training and testing data are different.
SIG: A best practice is to consistently apply a set of (the same) testing metrics to each model trained. Common metrics to use for this purpose are accuracy, recall/precision, F1-score, the Receiver Operating Characteristic (ROC) curve, or the Area Under Curve (AUC), but many more variants are in use.
KVT: In our context, the important metrics are recall and precision. Low recall means we miss generating important alarms (false negatives) for important events such as a patient falling down, while low precision means we generate too many alarms (false positives), potentially swamping the workload of health care workers. Both false negatives and false positives are bad, but in our case, it’s crucial to avoid false negatives.
Operations and Governance
Finally, models need to be deployed to production, while typically being integrated into a broader software application. At this stage, many concerns also come together, such as, what prediction are our models providing, and how are they being used in practice? Are the predictions on time? Could we roll-back from an under-performing model or apply a critical fix quickly enough? For an AI company, particularly a start-up, the actual operations and required governance structure could weigh heavier than the actual engineering. How have the engineers at Kepler Vision Technologies made this a manageable burden?
Defining and measuring AI value in business
SIG: Development of AI components should normally have a clear business goal. In many cases, the AI component will be competing with existing, non-AI, solutions. For the AI team, it’s paramount to understand these business value expectations clearly and to formalize them as one or several KPIs. Kepler seems to have a pretty clear-cut offering with its Night Nurse product, how does that translate to the AI component?
KVT: Workers in the elderly care domain, particularly night workers, experience higher levels of both workload and stress due to the many false alarms (or false positives) that current systems produce. Our AI therefore provides more value if it reduces the false positive rate. We use the false positive and negative rates as our primary metrics to evaluate models as they are being engineered. We also keep track of each false positive or negative that occurs in practice to improve model performance.
Automating model deployment and roll-back
SIG: Putting AI models into production is not much different than putting regular software into production, including the desire to automate the process. Automation prevents error, repetition of tedious effort, and increases speed, at least in theory. To what extent have you automated your deployment pipeline, and do you feel it has given you benefits?
KVT: Deployment of our models to production is fully automated. Essentially, we use Docker containers to serve one or more models, as an integral part of the broader application. The models themselves are kept in cloud storage, since they can become rather big. The models are synchronized to a container on demand, automatically. This way, it’s also possible to roll back to an older model version if there’s a need for that.
Monitoring operational models for quality and appropriateness
SIG: Once models are running in production, they will continuously be faced with previously unseen data. The underlying processes that generate the data may subtly change, eg. due to changes in the usage of the application or interface, the user population, or models slowly becoming out of date. What types of monitoring do you apply in practice to keep track?
KVT: We log each prediction made by each model, in order to later analyze any bad predictions that have occurred. Our modelers use the logging functionality to track performance of new or updated models in production. They have a low-tech approach for this right now, using their own spreadsheets to track, but more elaborate platforms for experiment tracking (e.g. Weights and Biases) could be considered here. We include detailed information on the model versions to facilitate later analysis.
Applying best practices for code quality
SIG: AI projects are, at their core, software engineering projects. Code is developed to engineer features, train and evaluate models, and finally deploy to production. The quality of the team’s codebase (ISO 25010 Product Quality, Maintainability) will, to a great extent, determine the success and sustainability of the project. However, not all AI team members are necessarily trained in writing code that can be easily changed or tested. As software engineers yourself, this must sound familiar, yet managing an actual AI team producing proper quality code can still be challenging. How do you manage to do so?
KVT: Essentially, we’re dedicated to precisely this task; to build and maintain the AI pipeline and automate it as much as possible. Of course, that also meant we had to train our AI modelers on writing and maintaining high-quality code, which isn’t something they were trained for specifically. As the software engineering team, we also develop tools to directly facilitate the data annotation (labeling) process and make it easy for modelers to select data to train their models. We use automated code quality tooling (Better Code Hub) to check coding guidelines across the entire AI pipeline and its tools in order to keep the code base maintainable.
The fields of AI and software engineering are rapidly developing, and we at SIG are happy to see cases where both come together nicely, as they do at Kepler Vision Technologies. The AI practices discussed in this article are part of our new solution, software assurance for Artificial Intelligence, where we also consider quality of code artifacts, technology choices, and overall trustworthiness.
References
- Software Engineering for Machine Learning: A Case Study, Amershi et. al., Microsoft, ICSE-SEIP, 2019,
https://www.microsoft.com/en-us/research/publication/software-engineering-for-machine-learning-a-case-study/. - What’s your ML Test Score? A rubric for ML production systems, Breck et. al., Google, NIPS, 2016,
https://research.google/pubs/pub46555/. - SE4ML – Software Engineering for AI-ML-based Systems, Kristian Kersting, Miryung Kim, Guy Van den Broeck and Thomas Zimmermann, Dagstuhl Seminar 20091, 2020,
SE4ML – Software Engineering for AI-ML-based Systems. - ML Engineering Best Practices, Alexandru Serban and Joost Visser, 2020,
https://se-ml.github.io/practices. - Data Engineering, Preparation, and Labeling for AI 2019, Cognilytica Research,
Cognilytica Joins PMI. - Continuous Delivery for Machine Learning, Sato et. al., martinfowler.com, 2019,
Continuous Delivery for Machine Learning. - Rules of Machine Learning: Best Practices for ML Engineering, Martin Zinkevich, Google, 2018,
https://developers.google.com/machine-learning/guides/rules-of-ml. - Software development best practices in a deep learning environment, Per John, Kepler Vision, Blog, 2019,
https://towardsdatascience.com/software-development-best-practices-in-a-deep-learning-environment-a1769e9859b1.