We analyzed the code of Cursor’s AI-built browser FastRender
In this article
Summary
FastRender is an impressive Agentic-AI experiment from Cursor in a brutally hard domain. Cursor’s swarm of coding agents produced a browser engine with over 3 million lines of code in just a week.
Important note: FastRender was explicitly presented as an experiment by Cursor, not a production browser.
We analyzed the code by running it through Sigrid®, our software portfolio governance platform:
Our analysis shows
- FastRender’s codebase equals roughly 110 person-years of Rust, with a maintainability score of 1.3/5 – placing it in the bottom 5% of systems we see on the market.
- FastRender’s architecture quality scores 2.1/5, indicating tightly coupled components and low modularity – making change risky and expensive in an already complex domain.
A closer look at FastRender
When Cursor CEO, Michael Truell, posted on X that he built a *kind-of* working browser engine with the GPT-5.2 model in Cursor, a lot of people took notice.
A project consisting of over 3 million lines of code and thousands of files – something that would usually take a team months – appeared in a week, and it was driven by AI agents, writing code for 168 hours straight.
FastRender is explicitly presented as an experiment, not a production browser.
“We’ve been experimenting with running coding agents autonomously for weeks. Our goal is to understand how far we can push the frontier of agentic coding for projects that typically take human teams months to complete.”, said Wilson Lin, the Cursor engineer behind FastRender.
That’s an important distinction and exactly what makes it interesting. It’s a glimpse of what a small team using AI can build in a short time in one of the most challenging domains in software engineering: web browsers.
At Software Improvement Group, we were curious about what this kind of AI-generated system looks like under the microscope.
So, we analyzed the public FastRender codebase using Sigrid®, our software portfolio governance platform. In this article, we share what we saw in the code – and what that means for organizations when AI agents can build such complex systems independently.
How FastRender *kind of* works and why that’s a big deal
FastRender started as an experiment inside the Cursor ecosystem. Using their AI-native editor and swarms of coding agents, a small team set out to build a browser rendering engine in Rust.
In an interview, blogger Simon Willison (not to be confused with interviewee and Cursor Engineer, Wilson Lin), showed how FastRender was able to load and render real sites such as GitHub, Wikipedia, and CNN.
Why is building a web browser in just a week so impressive?
Browsers are among the most complex systems to build. If you’re wondering why, just consider for a moment: They enable you to access the entire internet.
A browser engine is the component of a web browser that functions “behind the scenes” to fetch web pages from the internet and transform their content into readable, watchable, or audible formats.
Next to the engine, there is the browser user interface, which includes elements like tabs, toolbars, and menus. The browser interface is also known as the “chrome.” Not to be confused with Google’s browser Chrome, or their open-source engine Chromium, but it’s a pretty safe bet that that’s where it got its name from.
The public opinion about Cursor’s FastRender is mixed
Naturally, Cursor’s AI-driven workflow that produced a somewhat functioning browser engine in just a week is genuinely impressive. And as you would expect, it got lots of attention.
Yet, the reactions were quite diverse, ranging anywhere between “Wow” and “Meh”. For example:
In a write-up and interview with FastRender’s creator, Wilson Lin, Simon Willison focused on the experiment’s design.
“The thing I find most interesting about FastRender is how it demonstrates the extreme edge of what a single engineer can achieve in early 2026 with the assistance of a swarm of agents.” – Simon Willison.
While blogger Stefan Todoran argued that, contrary to some headlines, the FastRender browser was not built “from scratch”.
“It is also clear from the planning documents the agents wrote for themselves that existing open source browser implementations such as Mozilla’s Servo and Google’s Chromium served as guides to the agents, further undermining the “from scratch” claim” – Stefan Todora.
Another blogger, Mehmet Özel, framed FastRender as a sign that the timeline for attempting extremely ambitious projects has been dramatically compressed.
“While it’s far from production-ready, the implications are hard to ignore.” – Mehmet Özel.
And Steven J. Vaughan-Nichols wrote an opinion piece in The Register, urging readers to “check the repo before believing the hype”, arguing that Cursor may currently be “better at marketing than coding”.
What do I say?
Well, the process is extremely impressive. The resulting product warrants closer scrutiny. The verdict depends on your expectations.
Our contribution is to add quantitative measurements of maintainability and architecture quality to that picture. Using the same models, we applied to over 400 billion lines of code, across 300+ technologies and tens of thousands of systems.
How we analyzed the FastRender codebase
For this article, we focused on two dimensions that are both fundamental and measurable: maintainability and architecture quality. Both can be benchmarked against a large body of industry systems, and both have clear business implications.
- Maintainability – how easy is it to understand, change, and test the code?
- Architecture– how are responsibilities split and how do components depend on each other?
We didn’t try to re-implement browser conformance tests. Instead, we used static analysis and architectural reconstruction to see what the code tends to encourage over time: fast evolution or fragile, quick fixes? clear structure or tangled dependencies?
We used Sigrid®, our software portfolio governance platform, to calculate these metrics and visualize how FastRender is put together. We then compared its profile qualitatively to systems of a similar size in our broader benchmark.
In other words: we wanted to see whether the impressions from manual reviews – “messy”, “spaghetti”, “far from production-ready” – show up in the data, and how they compare to the rest of the market.
We also observed points around security, use of open-source libraries, and how Rust is used in practice in this codebase. Those deserve a deeper dive of their own; if you’re interested in a follow-up on those aspects, feel free to connect and let me know directly.
Sigrid’s findings when analyzing the FastRender codebase
1. The size of FastRender codebase: roughly 110 person-years of Rust
The FastRender technology stack corresponds to roughly 110 person-years (PY) of Rust development effort.
In other words, given average market productivity for Rust, about 110 developers would need a full year to write this amount of Rust code in its current state.
The Cursor swarm produced this in a tiny fraction of that time.
From a quality and governance perspective, this is the headline. We are no longer talking about a handful of generated functions. FastRender sits in the same ballpark as many early-stage products we see in the industry in terms of size and functional scope.
That makes it a serious test case for what AI-generated code looks like structurally.
2. Maintainability of FastRender: 1.3 stars, bottom 5% of the market
Maintainability refers to how effectively and efficiently a system can be modified to improve it, correct it, or adapt it to change. At Software Improvement Group (SIG), we also often refer to this as ‘build quality’.
We developed a model based on the global standard on Software Quality (ISO 25010) to measure maintainability using a 1-5 star rating. This model uses a TÜViT-certified dataset, representing the global market, so scores are comparable and audit-ready.
Our platform, Sigrid®, uses this model to analyze the maintainability score of source code.
We ran the publicly available FastRender code repository through our platform and found that FastRender’s code base scored 1.3 stars out of 5.
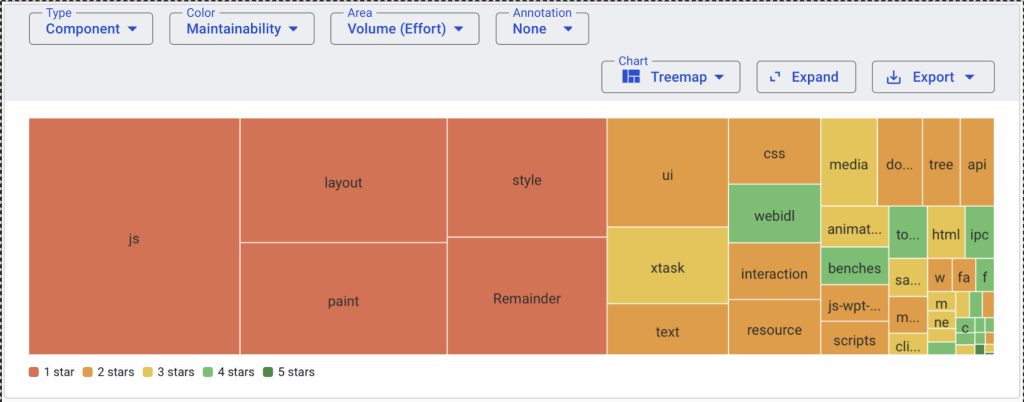
Let’s put that score into context:
- A four-star score is our target for a new system: good maintainability at a reasonable cost.
- Five stars represent excellent quality, achieved with additional effort and cost.
- At 1.3 stars, FastRender falls into the 5% least maintainable systems we encounter in the market.
Practically, this implies that making changes to FastRender’s codebase will, on average, take about four times longer than making comparable changes in a four-star codebase. Over the lifetime of a system, that multiplier translates directly into higher cost, slower delivery, and more pressure on teams.
For an experiment, this is not a failure. But if a system with this profile were to become business-critical, organizations would feel that drag very quickly.
3. Architecture of FastRender: high inherent complexity in an already complex domain
Rendering web pages is inherently complex. Browsers have to deal with multiple specifications, untrusted input, asynchronous behavior, and tight performance constraints.
All the more reason to keep the underlying architecture as clear as possible. Otherwise, you end up with two problems instead of one: a complex domain and a complex system.
Sigrid uses SIG’s Architecture Quality model to provide insight into the ability for an application to evolve as business needs change.
The basic idea comes down to modularity within an architecture, specifically how well are systems in the landscape defined via components and the degree to which these components can easily be worked on in isolation or swapped out with new functionality.
Our architecture metrics for FastRender show 2.1 stars out of 5, score below what we typically see in the broader software market.
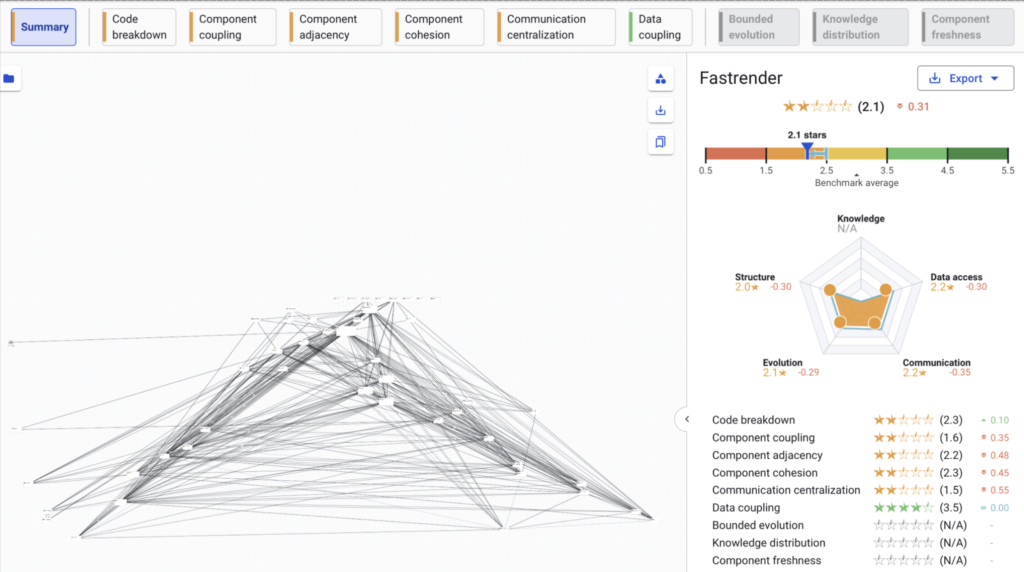
In plain language, this suggests that:
- Responsibilities are spread in ways that make it harder to isolate and reason about individual parts.
- Components are more tightly interwoven than is healthy for long-term evolution.
- Changes in one area are more likely to have unexpected side effects elsewhere.
Again, for a research project exploring what AI agents can do, this is understandable. But it also means that, if FastRender or a similar system were to move toward production, substantial architectural simplification and refactoring would be advisable.
The risk of creating legacy-like systems with AI
Looking at these measurements together raises a deeper question.
FastRender demonstrates that AI-assisted workflows can produce, in a week, the kind of system that would normally take a large team months or years to build. At the same time, its maintainability and architecture profile look more like what we usually associate with legacy applications: hard to change, hard to reason about, and expensive to evolve.
Can’t we just use AI to improve the maintainability and architecture of an AI-generated system?
It’s tempting to assume that AI could also maintain such systems faster.
In practice, current models struggle with large, organically grown legacy codebases, especially when responsibilities are tangled and tests are sparse. While AI can generate and even help review code, they’re still limited. It relies on associative, pattern-based reasoning, which makes it fast but not always accurate. AI can miss critical flaws because it doesn’t have the full system context or understanding of your architecture.
What about just regenerating a new version every week?
Another idea is to avoid maintenance entirely and simply regenerate a new version each week. That sounds attractive in theory, but runs into real-world constraints:
- Cost. The original experiment was not free – while the exact cost is not known, it was estimated that between 10 and 20 trillion tokens were consumed and based at then‑current list prices for frontier models, would’ve cost several million dollars.
- Testability. When functionality can’t be cleanly isolated, it becomes very difficult to build reliable automated tests. That makes it hard to offer serious guarantees to customers or regulators.
- Security and reliability. Each new version would require a fresh review of exposed surfaces, failure modes, and performance characteristics.
In closing
Can a swarm of coding agents build a web browser rendering engine? Such rendering engines are notoriously difficult to build.
The answer today is not yet, at least not without extensive human intervention. But we’re getting interestingly close, and Fastrender is an impressive research project.
In other words, AI can dramatically compress the time it takes to create complex systems. However, without governance, it can just as quickly create a new class of legacy: large, opaque, and hard to trust.
Sigrid® brings clarity to complexity, combining deep code insights with expert guidance to help you govern your software landscape and harness the full power of AI.
Ensure your technology is a driver of success, not a source of risk. Read more here.
About the author

Werner Heijstek
Werner Heijstek is the Senior Director at Software Improvement Group and host of the SIGNAL podcast, a monthly show where we turn complex IT topics into business clarity.
Helping organizations govern the software their business runs on by enabling control of software cost, risk & speed in the AI era| Business–IT alignment | Host of the SIGNAL podcast | Senior Director at Software Improvement Group.