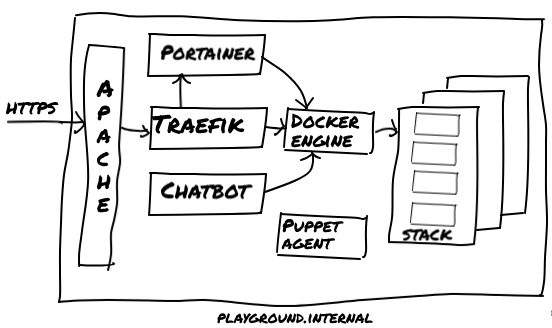
At SIG, we needed more flexibility and ease-of-use from our test/acceptance environments. Therefore we have started replacing our application-specific test/acceptance servers by a simple, yet flexible Docker-based cluster. The cluster itself is provisioned and configured automatically as all the specs are expressed as code and configuration. Now, developers can deploy any branch of a software system they’re working on onto the cluster, as long as it’s packaged as a (set of) container(s). The use of a Traefik proxy allows the developers to control how the application can be accessed, simply by adding labels to the container(s). Finally, a simple chatbot listens in a dedicated Slackchannel for commands, deploys the desired application branch/version (using parameterized docker-compose.yml files), and responds with the resulting URL in the Slack channel. This solution makes our lives more fun and easy (and helps us to get things done).
A generic Docker-based cluster, replacing test/acceptance servers
Introduction
When developing software applications it has been common practice for a long time to build and configure dedicated test and acceptance environments, next to the production environment. Separate environments allow for different types of testing (integration, performance, security, acceptance, etc.), in order to promote new releases of the application software using a structured process. Performing the actual deployments however, is not a task that every developer was able or allowed to do.
While testing and acceptance of new releases is still important today, new ways to approaching this have emerged. Container technology like Docker helps in creating uniform deployment packages, while container orchestration tools like Docker Swarm or Kubernetes help in performing and optimizing the actual deployment in a uniform way. Finally, build pipelines, APIs, and even chatbots can be used to increase accessibility and traceability of standardized tasks, like application deployments, for developers.
Challenges to address
Here’s an overview of improvements we wanted to achieve, in no particular order:
Make deployment activity accessible to all developers
Ease of use
Support multiple versions/branches of the same application in parallel
Access to deployed applications via URLs that look similar to production
Full isolation between stacks, e.g. no shared databases
Deploy microservice “landscapes” in one go
Optimize server utilization
Traditional approaches are no longer meeting our needs
Developing more than a hand-full of software applications used to mean maintaining a bunch of test/acceptance servers, as part of the Development-Test-Acceptance-Production (DTAP) setup.
DTAP setup for each application requires maintaining many servers
Years ago, we’d install applications manually for testing on any test server with some capacity available, and web applications would be configured to listen for HTTP traffic on a port that happened to be available. While we would get the application to work in order to do the testing, the setup was not similar to the production environment.
Later, leveraging the automation benefits of Software Defined Infrastructure(SDI), at SIG we adopted the philosophy that (virtual) servers should be simple and run just 1 application, and resembling as much as possible the application’s production server setup. This however has lead to dozens of virtual servers that are virtually doing nothing, most of the time. These servers were configured with application-specific software packages and settings, used fixed application URLs and supported only one version or branch per application at a time. Although everything was in code and configuration, starting a second server to deploy a different branch of the same application usually felt like too much trouble.
Docker to the rescue!
Last year we introduced the next generation of our test/acceptance environment: a generic, flexible, Docker-based testing platform. Although already becoming a trend, installing and operating Kubernetes on-premise wasn’t feasible at the time, nor was using a managed Kubernetes as a Service. Therefore, leveraging existing experience, we built a Docker Swarm setup, using our preferred tools for setting up servers: Terraform and Puppet. This platform can host multiple, relatively short-lived container stacks for test and acceptance purposes, offering the needed flexibility.
Dev-Docker-Production in practice
As some developers had a personal “sandbox” server, and this testing platform is slightly bigger and supports more variation, we call it “the Playground”.
Since not all software developers have experience with (or access to) our Terraform/Puppet setup, a key feature of the Playground is that we don’t use Puppet to perform application deployments. Instead, developers can deploy and remove containers or (branches of) application stacks (specified as docker-compose.yml files) themselves, and do so in several ways:
The command line interface: docker run or docker stack deploy, for those colleagues who maintain a strict “command-line unless” policy
Web interface: Portainer
Chatbot: #playground channel in Slack
One downside still, the resulting URLs were not yet very flexible, as they were limited to a set of predefined proxy rules mapping onto container port numbers.
Traefik to the rescue!
A great improvement was introducing Traefik to the Playground, a very versatile reverse proxy tool that dynamically updates its proxy rules. And best of all: it supports Docker as backend and creates proxy rules on-the-fly when a docker container or stack is deployed, by inspecting the container’s labels. Combined with a wildcard DNS entry and a wildcard certificate, developers can specify the desired URL via container labels upon deployment of their container (stack).
So now we can deploy a container stack consisting of, say, a webapp, a database, and an authentication server stub and access it via e.g. https://my-webapp-branch.playground.internal/ or https://my-webapp.playground.internal/branch/, just as we’d like.
Improving the experience of actual deployment
We evaluated Rancher 1.6 for a while, and concluded it wasn’t the best fit for our needs. As using the Docker CLI through SSH was also not everyone’s favorite approach, we developed a small Python script. The script would derive application and branch name from the current working directory and git branch, perform a bunch of search-replaces in the local docker-compose.yml file, copy this file to the Playground, SSH into the Playground, pull the required container images, and execute a docker stack deploy. Then it would print the URL at which the application should become available to stdout. While convenient at first, the script was hard to make generic for many projects as it quickly contained a lot of application-specific search-replace logic.
Chatbot to the rescue!
The idea existed for a while already, finally there was a free evening on the couch to start building an experimental chatbot, as an alternative to the Python script. We had some experience building a chatbot before, using ChatterBot, and now wanted to see which other frameworks are out there. We found Errbot, a nice chatbot framework in Python, with many available plugins including support for our current chat platform of choice: Slack.
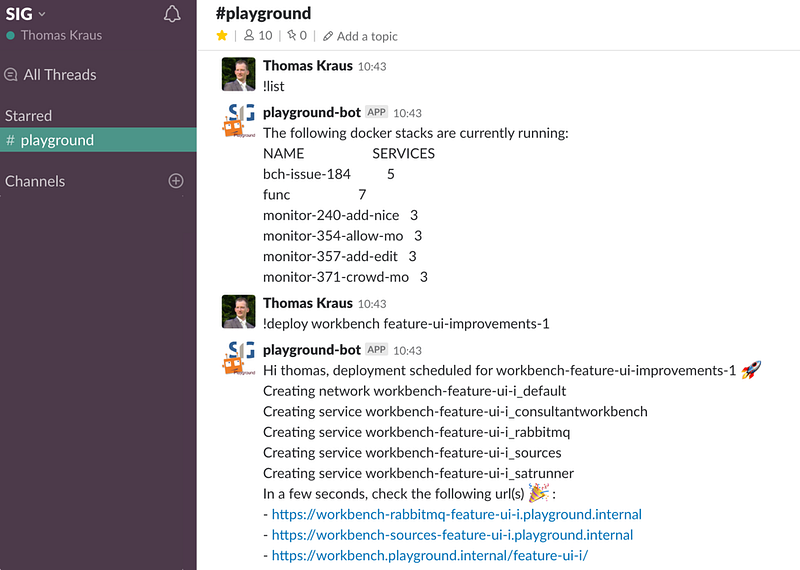
Here’s how we can list currently deployed stacks and deploy a new branch of an application we’re working on.
Listing and deploying container stacks at our internal test environment
Although no Docker plugin existed for Errbot yet, one really just needs a few lines to create an Errbot plugin, and just a few command line commands for docker stack were sufficient for our needs. So a little while later a first version was running on the Playground. See a snippet of the plugin implementation below, for brevity some input validation and helper methods were left out.
from errbot import BotPlugin, botcmd
import subprocess
class Docker(BotPlugin):
"""
A pragmatic Errbot plugin to list and manipulate docker stacks
"""
@botcmd
def list(self, msg, args):
"""
List containers currently deployed
"""
result = 'The following docker stacks are available:\n'
result += subprocess.getoutput('docker stack ls')
return result
@botcmd
def deploy(self, msg, args):
"""
Deploy a new docker stack (branch of a known app)
"""
result = 'Hi ' + msg.frm.nick + ', '
split_args = args.split(' ')
app = split_args[0]
branch = split_args[1].replace('/','-').replace('@','-')
yaml = get_docker_compose_yaml(app)
yaml = replace_placeholders(yaml, app, branch)
output, urls = do_deploy(yaml, app, branch)
result += 'deployment scheduled for {}-{}:rocket:\n {}\n'.format(app, branch, output)
result += 'In a few seconds, check the following url(s) :tada: :\n'
for url in urls:
result += '- {}\n'.format(url)
return result
As developing the Errbot plugin went fast, most time actually went into figuring out the required development dependencies on Alpine Linux in order to produce a small docker image from the build pipeline. Below you’ll find a working Dockerfile.
Finally, in order to have the Python code talk to the Docker daemon from within the container, we mount both /var/run/docker.sock as well as a ~/.docker/config.json (containing registry credentials) into the container — something you’d normally not do for security reasons: it essentially breaks the isolation Docker provides. In this case though, obviously, the entire purpose of the chatbot container is to manipulate the Docker engine.
FROM python:3.6-alpine
LABEL maintainer="info@example.com"
Within days this chatbot was used more often for deploying application stacks than Rancher and the Python script combined.
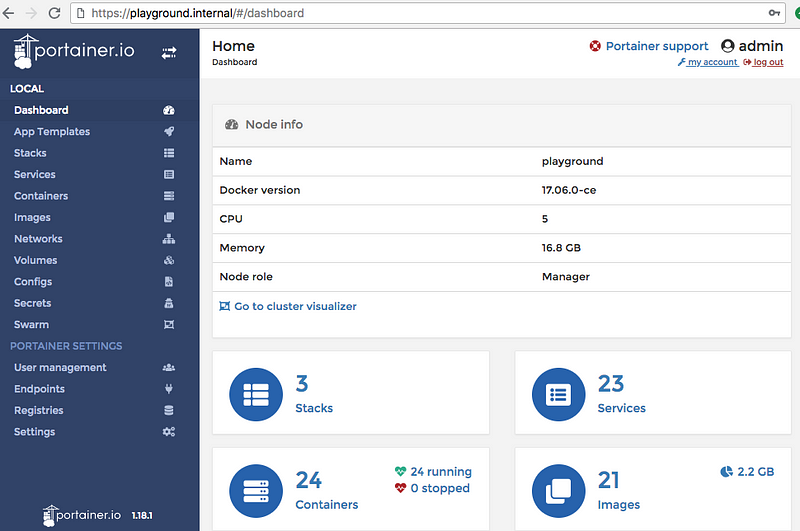
So no web-based UI? Portainer to the rescue!
Finally, to allow for more fine-grained control than we wanted to give in the chatbot, combined with the comfort of a nice web interface, we installed Portainer as an optional add-on. This is actually the lightweight UI to manage an existing Docker Swarm cluster we had been looking for. It provides a simple overview of all resources on the cluster, and simply allows for uploading/editing a docker-compose.yml file, as well as removing existing stacks. Finally, a simple authentication / authorization mechanism is provided as well. Similar to the chatbot, Portainer requires to have /var/run/docker.sock mounted into the container.
Portainer: a lightweight web UI for managing Docker Swarm
Conclusion and future work
The new approach to testing our software is helping us in several ways as it has increased efficiency and flexibility, and it’s also much faster to have an application (branch) deployed. For instance, we can now deploy feature branches for review by the product owner, and keep these available for some days if needed, while in parallel we deploy branches to quickly verify bug fixes. Note that these stacks are fully isolated (including databases or other middleware) so any testing activities on one application stack does not influence the data or behavior of another stack.
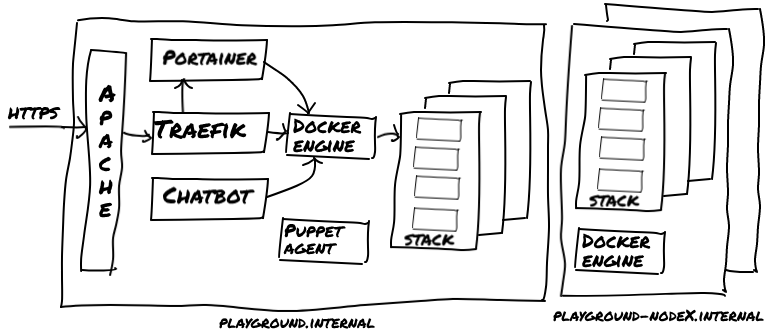
Currently we just have one beefy (virtual) machine that makes up the entire Playground, but we already experimented a bit in Puppet code to have additional machines joining an existing Docker Swarm cluster as worker nodes. So when more capacity is needed, the platform can scale quickly, transparently to the end user, as depicted below.
Future scalability: adding more machines that join the Playground’s Docker Swarm cluster as worker nodes
Build pipelines may then perform automatic (re)deployments for each branch of each application onto the cluster, leaving it up to the developers to click the link and test that particular application version as needed. Likely the chatbot will stay, as it can also provide on-demand info on currently deployed stacks, perform scheduled clean-up tasks or periodically blurt out some statistics in the Slack channel.
All in all, with this setup we managed to address all challenges listed above and have put the deployment of application branches at the developer’s fingertips. If you’re curious about more implementation details, leave a remark and I just might work on a setup that’s fully open source.
This blog was also posted on Medium by Thomas Kraus
Let’s keep in touch
We'll keep you posted on the latest news, events, and publications.