Agentic AI in software engineering works best with a human in the loop
In this article
Summary
We used Sigrid®, our software portfolio governance platform, to compare three systems that are built with AI (but all in different ways).
- FastRender (AI agents, no human in the loop)
- Claude’s C Compiler (Autonomous LLM, no human in the loop)
- OpenClaw (Human in the loop)
All three codebases were analyzed on their publicly available repositories. We focused on maintainability and architecture, using the same ISO 25010-based 1–5 star model we use across more than 30,000 systems in our benchmark.
In non-technical terms, when we analyzed these code repositories we asked two simple questions:
- Maintainability: How easy will it be to make changes to this system over time?
- Architecture: How well can you understand the structure and interconnections within the system?
| AI-built system | Maintainability score: | Architecture score: |
|---|---|---|
|
FastRender (AI Agents-only) |
1.1/5 |
2.2/5 |
|
Claude’s C Compiler (Autonomous LLM team) |
1.9/5 |
2.4/5 |
|
OpenClaw (Human in the loop) |
3.1/5 |
4.4/5 |
While the AI-only systems (FastRender, Claude’s C Compiler) reached impressive functionality they scored in what we’d normally consider legacy-like territory on maintainability, with weak to middling architecture.
However, human in the loop development (OpenClaw) landed much closer to what we’d expect from a system that can evolve better over time.
The rise of Agentic AI in software development
Three years ago, a professional developer using AI felt novel; today, it’s normal. According to the AI Boardroom Gap report, 90% of technology professionals now use AI at work, and assistants draft code, suggest fixes, and speed up routine tasks.
Today, the AI agent doesn’t just suggest code—it volunteers to do the whole task. AI assistants like Cursor, Replit Agent, Devin, GitHub Copilot Workspace, and others all pitch a similar promise: let the AI agents build it, you just describe what you want.
This is what people mean by agentic AI in software engineering: not just a chatbot that answers questions, but software “workers” that can plan, write, test, and repair code on their own.
Can you imagine the potential productivity boost? Indeed, and the upside seems real: 52% of developers agree that AI tools and/or AI agents have had a positive effect on their productivity.
But speed is only half the story. If agents can build an entire system in days, what kind of system does it produce?
That’s the question we set out to answer in this follow-up.
This time, instead of looking at a single experiment, we compared three real AI-era codebases: two built almost entirely by agents, and one where a human stayed firmly in the loop.
We analyzed the following 3 AI-built systems
1. AI agents only: FastRender
To see how far they could push agentic AI, Cursor picked an ambitious target: build a web browser engine from scratch in Rust. They pointed the agents at an empty repo, turned them loose, and let the system run for a week.
By the end, the agents had produced over a million lines of Rust spread across around a thousand files and a browser that can load real sites.
Cursor has been clear that FastRender is an experiment, not a production browser. The point was to see what happens when hundreds of agents share a single codebase for days on end — how well they coordinate, how much code they can write, and what kind of system you get if humans largely stay out of the way.
In our earlier write-up, we treated FastRender as exactly that: a glimpse of what a swarm of agents can build in a brutally hard domain when speed and scope are the main goals.
2. Autonomous LLM team: Claude’s C Compiler
Claude’s C Compiler came out of a simple but bold challenge inside Anthropic: could a group of AI assistants, working together, build a real C compiler if you mostly left them alone?
What is a C Compiler you ask?
A C Compiler is a core piece of plumbing in software development — it takes human-written C code and translates it into the low-level instructions that computers understand.
At Antrophic, Researcher Nicholas Carlini set up sixteen Claude agents as a kind of “AI team”. He pointed them at an empty repository and gave them a clear goal in plain language: build a C compiler in Rust that can handle something serious, like the Linux kernel.
The Linux kernel is the core ‘engine’ of the Linux operating system — the part that talks to the hardware and manages everything else that allows you to run applications.
From there, the AIs did most of the work. They opened tasks, wrote code, ran tests, and fixed their own mistakes. The human work was mainly in setting up the environment and the test harness that told the agents whether they were on the right track. This is where it differs from Cursor’s experiment.
Over a couple of weeks and a few thousand test runs, the AI team produced a new compiler with roughly a book’s worth of Rust code and proved it could compile Linux and other well-known open-source projects.
Carlini has been clear and stated that this compiler isn’t ready to replace the long-standing, industry-standard open-source C compiler: GCC. It’s slower, it leans on existing tools for a few tricky steps, and the code is not what an experienced compiler engineer would ship.
3. Human in the loop: OpenClaw
OpenClaw sits in a very different place than FastRender or Claude’s C Compiler. It isn’t a lab demo. It’s something already in production and many people started using.
OpenClaw is an open-source personal AI assistant created by Austrian developer Peter Steinberger. It runs on your own machine and connects AI models to the tools you already use: e-mail, calendar, files, and chat apps like WhatsApp, Telegram, and Discord.
Under the hood, OpenClaw is a local “gateway” for AI agents. You talk to it in a chat window, and it can fire off pre-built “skills” that read and write files, run commands, call APIs, or talk to other services. Instead of a closed, hosted assistant, you get something you install yourself and can extend with thousands of community-made skills.
That mix of power and control is a big part of why it exploded in popularity and now has a very active ecosystem and even its own fan meetups.
The flip side is risk. Because OpenClaw can touch so much of your digital life, a bug or misconfiguration can have real impact. Recently, a flaw dubbed ClawJacked allowed a malicious website to quietly hijack a locally running OpenClaw agent by brute-forcing its password over a local connection. In other words: just visiting the wrong page could let someone else steer your personal AI. The issue was patched within about a day, but it triggered a wave of hardening and a lot more scrutiny of how OpenClaw is configured and tested.
For our comparison, that makes OpenClaw interesting in a different way. It’s built and evolved in public, with maintainers who respond quickly when something goes wrong, and a community that reviews changes and adds features. People use AI coding tools around it, but humans still decide how the system is structured, which changes are safe to merge, and how to respond when vulnerabilities like ClawJacked appear.
It’s a good example of AI-assisted development where AI does a lot of the work, but humans stay responsible.
What we found when we analyzed these AI-built systems
We analyzed all three codebases on their publicly available repositories. We focused on maintainability and architecture, using the same ISO 25010-based 1–5 star model we use across more than 30,000 systems in our benchmark.
In non-technical terms, when we analyzed these code repositories we asked two simple questions:
- Maintainability: How easy will it be to make changes to this system over time?
- Architecture: How well can you understand the structure and interconnections within the system?
Four stars is where we’d like a new system to start its life. Anything below two stars behaves like legacy software: you can change it, but it tends to be slow, risky, and expensive.
With that in mind, here’s what we saw.
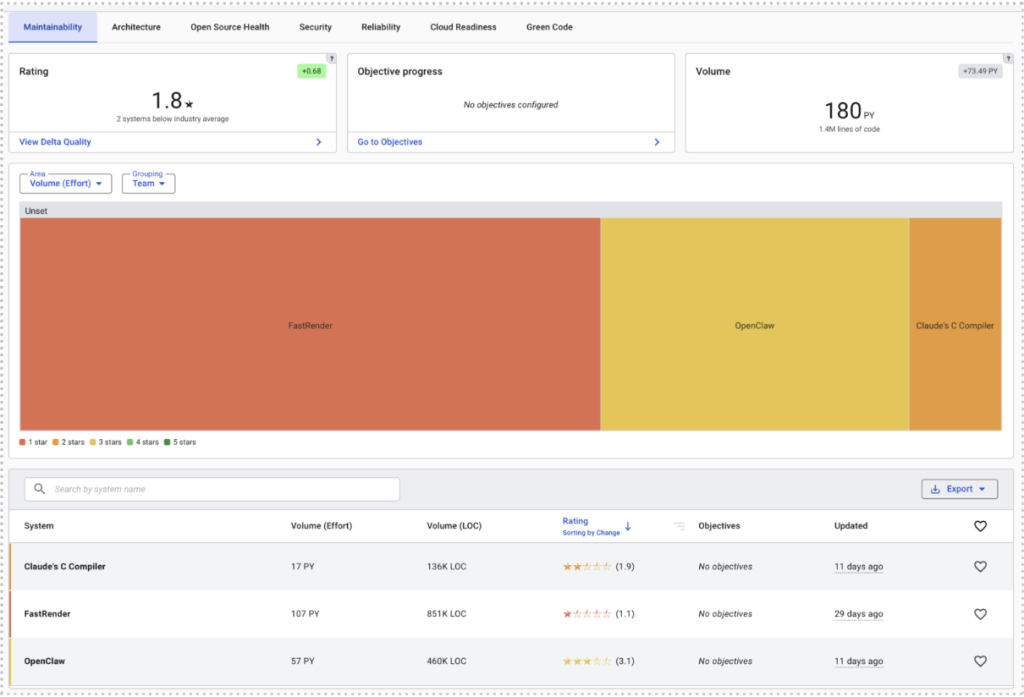
The quality of FastRender
FastRender is the purest “agents only” example in our comparison, and it shows. On our scale, it scores about 1.1 out of 5 for maintainability and 2.2 out of 5 for architecture.
The codebase is large and ambitious for its time-to-build, but its maintainability and architecture profiles are weak. Tightly interwoven components, uneven abstractions, and limited test isolation make change risky.
To compare, this is the kind of profile we usually see in systems that have grown organically for years without much architectural care: lots of hidden connections, features woven through multiple places, and very little room to move without bumping into something else.
In practice, that means a team picking up FastRender would spend a lot of time just figuring out where it’s safe to touch.
The quality of Claude’s C Compiler
Claude’s C Compiler does better, but it’s still not where we’d want a fresh codebase to be. It lands around 1.9 out of 5 on maintainability and 2.4 out of 5 on architecture.
We see pockets of coherent modules mixed with duplicated logic, ad hoc interfaces, and tests that don’t form a cohesive safety net. Architecture quality is marginally higher than FastRender, yet still suggests brittle boundaries.
You can see that in how the code is organised. Some parts form clear, sensible modules. Others repeat ideas, improvise interfaces, or stitch special cases on top of each other. There is a test harness, which is what allowed the agents to get as far as compiling the Linux kernel, but it doesn’t change the basic picture: this is still a system where changes will be delicate and take time.
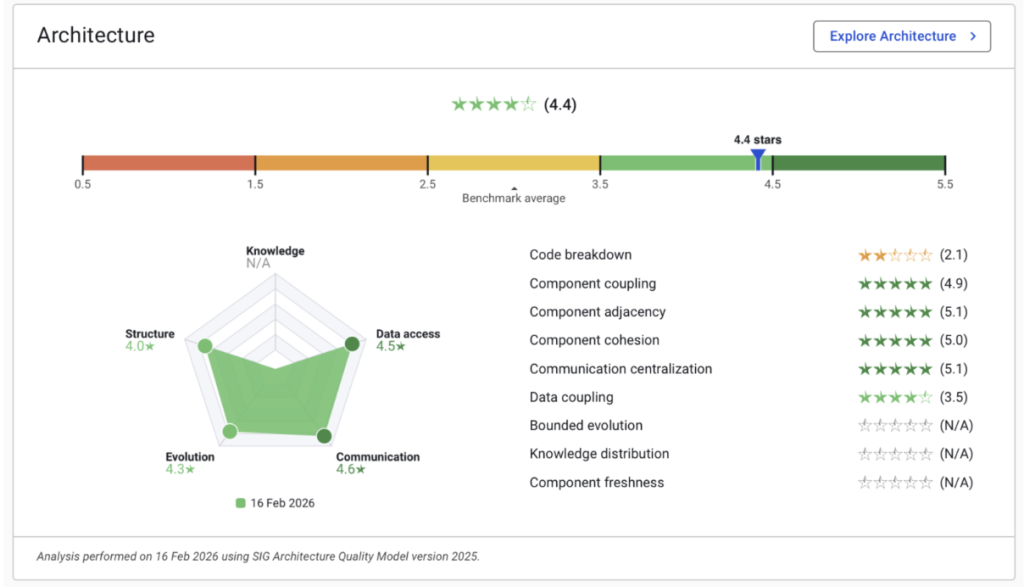
The quality of OpenClaw
The standout in this comparison. Its maintainability score sits just above 3 out of 5, and its architecture score is about 4.4 out of 5.
Its maintainability score places it within a workable range for ongoing development, and the higher architecture score indicates strong modularity and clean separations. Changes are more likely to be local, testing is easier to structure, and responsibilities are clearer.
The code has a clearer shape: you can tell where the boundaries between parts are, which pieces talk to which, and how you might add a new skill without threading it through the whole project. Tests are easier to place around components. Changes are more likely to be local instead of rippling everywhere.
4 reasons why human in the loop improved the quality of an AI built system
Looking across the three systems, the differences in qualities have little to do with the capabilities of the AI agents and more with humans shape and constrain them.
Four themes stand out.
1. Design boundaries and modularity
In OpenClaw, a human architect defined domains and module boundaries before and during AI generation. That gave the models a template to fill instead of inventing structure on the fly.
In other words, upfront human choices about components and interfaces created a shape for the code that the model’s generation could follow. This reduced implicit coupling and copy-paste propagation
2. Test strategy and traceability
Generally speaking: An AI assistant modifies what it can see. Clear test seams give it safer ways to change behavior and when humans enforce a test strategy, they also steer where agents can and cannot be creative.
OpenClaw’s contributors used tests as anchors for design: unit seams, fixtures, naming conventions, and targeted regression tests around tricky integrations. In the AI-only systems, tests are often seen as by-products of the experiment rather than first-class design artifacts.

3. Consistency and dependency hygiene
Humans pulled the code back to a consistent vocabulary and structure, rationalized library choices, and removed redundant utilities that often creep into AI-only runs.
By contrast, AI-only runs show more “drift”: similar ideas implemented multiple times, inconsistent naming, and libraries introduced for a single use and never cleaned up.
4. Guided refactoring and scope control
Human oversight kept the scope aligned to the architecture and used the model for targeted refactors, avoiding the “append more code until it works” pattern that drags maintainability down.
Practical steps to govern Agentic AI in software engineering
1. Put a human in the loop early and keep them there
Make sure there is a human who owns each AI-built or AI-heavy system. Not “owns the prompts”, but owns the system:
- How it’s sliced up,
- What “good enough” structure looks like,
- When you’re okay with agents changing things.
If nobody feels responsible for that, the agents will quietly make those decisions for you.
2. Adopt quality guardrails for AI-generated code
Set some explicit guardrails for AI-assisted code paths. For example, use architecture “fitness functions” that forbid cross-layer calls, enforce module boundaries, and limit risky dependency patterns. Add static analysis thresholds to cap complexity and code duplication and to prevent critical dependency cycles.
On the testing side, agree minimum coverage for core modules and use mutation testing where behaviour is safety-critical. These rules don’t need to be perfect from day one, but they should exist—and they should apply to AI-written code just as much as to human-written code.
3. Treat AI agents like power tools
If you wouldn’t merge a change from a junior dev without looking at it, don’t let an agent do it either.
Use AI where it really helps: let it scaffold new components and APIs from human-defined designs, handle boilerplate, migrations, and repetitive refactors under review, and generate candidate tests from specs and logs that you then curate. In all of these cases, treat AI-generated changes as proposals that go through the same governance and review as human changes.
4. Make transferability a requirement
Regularly ask: “Could a new team take this over in three months?” Keep prompts, scripts, CI/CD workflows, and agent configurations versioned and documented. Use Sigrid to track maintainability and architecture trends over time, so you can spot when an AI-heavy system is drifting into “new legacy” territory.
5. Plan for iterative hardening
Schedule explicit refactoring and test-debt sprints for AI-built components. Treat architecture-score regressions in core modules as build failures, not cosmetic issues. Include security and dependency health in your AI code governance roadmap — particularly as popular agent frameworks like OpenClaw attract both innovation and new classes of vulnerabilities.
AI coding at scale, without losing control
Skilled engineers can guide AI development, and the importance of the human-in-the-loop is clear. But once agentic AI starts producing code at scale, the loop can move too fast for human review alone to keep up.
Agentic AI can accelerate software development fast. But speed on its own is not the goal. If you put a much faster engine into the same process, you also need better control to keep the system on the road.
That’s why we say, you need to keep Sigrid-in-the-loop. The software portfolio governance platform that helps teams keep pace with AI-generated code by making maintainability, architecture quality, and vulnerability risk visible while development can keep moving. Humans stay in control; Sigrid helps them to go faster, responsibly.
If you want to know whether your AI assisted coding is accelerating in the right direction, we’d be glad to take a look with you.
About the author

Werner Heijstek
Werner Heijstek is the Senior Director at Software Improvement Group and host of the SIGNAL podcast, a monthly show where we turn complex IT topics into business clarity.
Helping organizations govern the software their business runs on by enabling control of software cost, risk & speed in the AI era| Business–IT alignment | Host of the SIGNAL podcast | Senior Director at Software Improvement Group.
FAQs
What is Agentic AI?
In this article, agentic AI means AI systems that don’t just suggest code, but can act on their own:
- They plan work (break a feature into tasks)
- They write and edit files in your repo
- They run tests and try to fix failures
Tools like Cursor, Replit Agent, Devin, and GitHub Copilot Workspace all move in this direction: you tell them what you want, and they go off and change the codebase for you, often over multiple steps.
What is maintainability?
Maintainability measures how easy it is to test, change, and evolve a codebase. A well-maintained system allows for quick modifications, reducing costs and improving development speed.
Having a high maintainability score enables faster releases, better efficiency, and lower maintenance costs. And having a lower maintainability score tends to create friction, slow development, and increase IT costs.
What was the scope of this comparison?
What was the scope of this comparison?
For this article, we kept the scope deliberately tight. We only looked at:
We focused on maintainability and architecture quality, using the same ISO 25010-based 1–5 star model we use across more than 30,000 systems in our benchmark.
In each case, we analyzed the publicly available repositories as they were at the time of the study. We didn’t include any private forks, internal versions, or additional context from the teams behind them.
We also focused on static structure, not runtime behaviour. So we looked at the shape of the code and architecture, not how fast it runs or how many users it has.
What are the limitations of this comparison?
There are a few important caveats:
We didn’t re-run full test suites.
We didn’t independently verify correctness, performance, or security. For example, we didn’t re-run all of Claude’s C Compiler’s benchmarks, or execute OpenClaw’s full integration tests.
We focused on static analysis.
in this analysis we specifically used Sigrid’s static code analysis capabilities to see how the build quality and architecture quality relate to the market. This helps to understand how easy or hard they are likely to be changed over time.
We only looked at one point in time.
All three systems are evolving. Our results are a snapshot, not a final verdict on any of them.
We picked three visible examples, not a full market study.
FastRender, Claude’s C Compiler, and OpenClaw are useful reference points, but they don’t represent every way teams are using agents and AI in software development.
The results are best read as early signals: they show patterns we’re seeing when AI does most of the typing, not an exhaustive map of the whole landscape.
How do we measure maintainability?
We developed a model based on the global standard on Software Quality (ISO 25010) to measure maintainability using a 1-5 star rating. This model uses a TÜViT-certified dataset, representing the global market, so scores are comparable and audit-ready.
- A 4-star score is our target for a new system: good changeability at a reasonable cost.
- Scores below 2 stars typically indicate “legacy-like” characteristics: changes are slower, riskier, and costlier, even when the system is new.
What is software architecture?
Software architecture defines how a system is structured and how its components interact.
A system’s architecture dictates how well it adapts to business changes, integrates new technologies, and supports long-term growth. When architecture is too rigid, even small changes require major effort, slowing development and making it harder to scale teams efficiently.
How do we measure Software Architecture?
Our Architecture Quality Model has been developed to measure the degree to which an organization’s implemented software architecture within a line of business, often consisting of a collection of software systems/applications, is designed with evolution in mind.
Our Architecture Quality Model assesses five key factors that determine a system’s ability to evolve: structure (modularity), communication (data exchange efficiency), data access (ease of retrieval), evolution (independence of changes), and knowledge distribution (how well architectural expertise is shared). Each system is benchmarked against thousands of applications and rated from 1 to 5 stars, with higher scores indicating a more scalable and maintainable architecture.
How do we measure Software Architecture?
Our Architecture Quality Model has been developed to measure the degree to which an organization’s implemented software architecture within a line of business, often consisting of a collection of software systems/applications, is designed with evolution in mind.
Our Architecture Quality Model assesses five key factors that determine a system’s ability to evolve: structure (modularity), communication (data exchange efficiency), data access (ease of retrieval), evolution (independence of changes), and knowledge distribution (how well architectural expertise is shared). Each system is benchmarked against thousands of applications and rated from 1 to 5 stars, with higher scores indicating a more scalable and maintainable architecture.
What changed since your original FastRender analysis?
FastRender first appeared in an earlier article where we analysed it shortly after the Cursor team published their experiment. Since then, we’ve improved how Sigrid handles large Rust codebases, especially around call resolution and architecture reconstruction.
With the updated model, FastRender’s scores shifted slightly:
- Maintainability recalibrated from about 1.3 to 1.1 stars
- Architecture quality moved from about 2.1 to 2.2 stars
The exact numbers changed a bit, but the story didn’t: it still sits at the very low end of our benchmark for maintainability, with weak architecture for a system of its size.