The software quality models that SIG uses for its flagship product – Sigrid® – consist of several features. Typically, each characteristic aggregates and stores data from different sources, and calculates useful metrics, such as trends over time, libraries with the highest vulnerability risk, etc.
Then all these values are delivered to the browser, and customers can then filter, sort, and export the data to Excel and tailor it to their specific needs.
Up until now, each of our models’ characteristics had its dedicated user interface page and a single, unified “central hub” dashboard was missing from the platform.
While building this dashboard we learned a lot about how to leverage Spring Boot’s capabilities for running asynchronous workloads and how we could leverage that for this particular use case. At SIG, we believe that having the optimal data flow that minimizes response time is essential for the user experience of our products. Let’s dive in.
Introduction
At SIG, the majority of the tech stack for the backend teams consists of Java 17 and Spring Boot.
An essential concept for this blog post is that of concurrency. Most of our Java services code gets executed in a single thread per request, i.e., a single request from a client will usually be handled in its isolated thread. This is Spring Boot’s default model for concurrency.
Although Spring Boot can handle multiple concurrent requests thanks to the default configuration of its embedded Tomcat server, the idea is that without any additional configuration from our side, each request will be handled in a separate thread.
This workflow works very well for the vast majority of the use cases we have found so far, but when devising the new unified dashboard, we were presented with a new challenge: We wanted to be able to efficiently aggregate data from multiple different sources and backing services under a single, centralized view, so performance would become a factor in what the design of such dashboards would look like.
Framing the technical problem
Before diving into the approach that gave us a much higher-performing dashboard, it’s important to understand the exact technical problem and why we needed to design an optimal data-loading strategy.
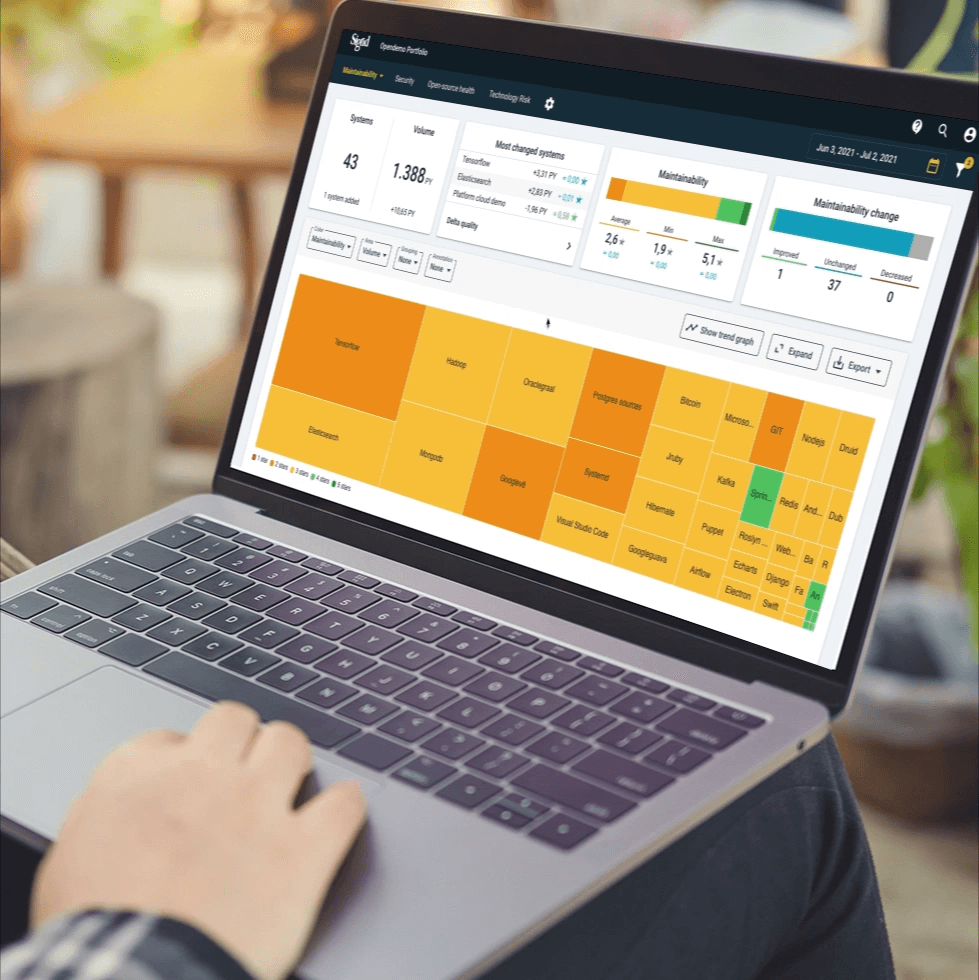
As described earlier, the idea is to have a “central hub” style dashboard where we combine multiple characteristics of our SIG model in a single, unified view:
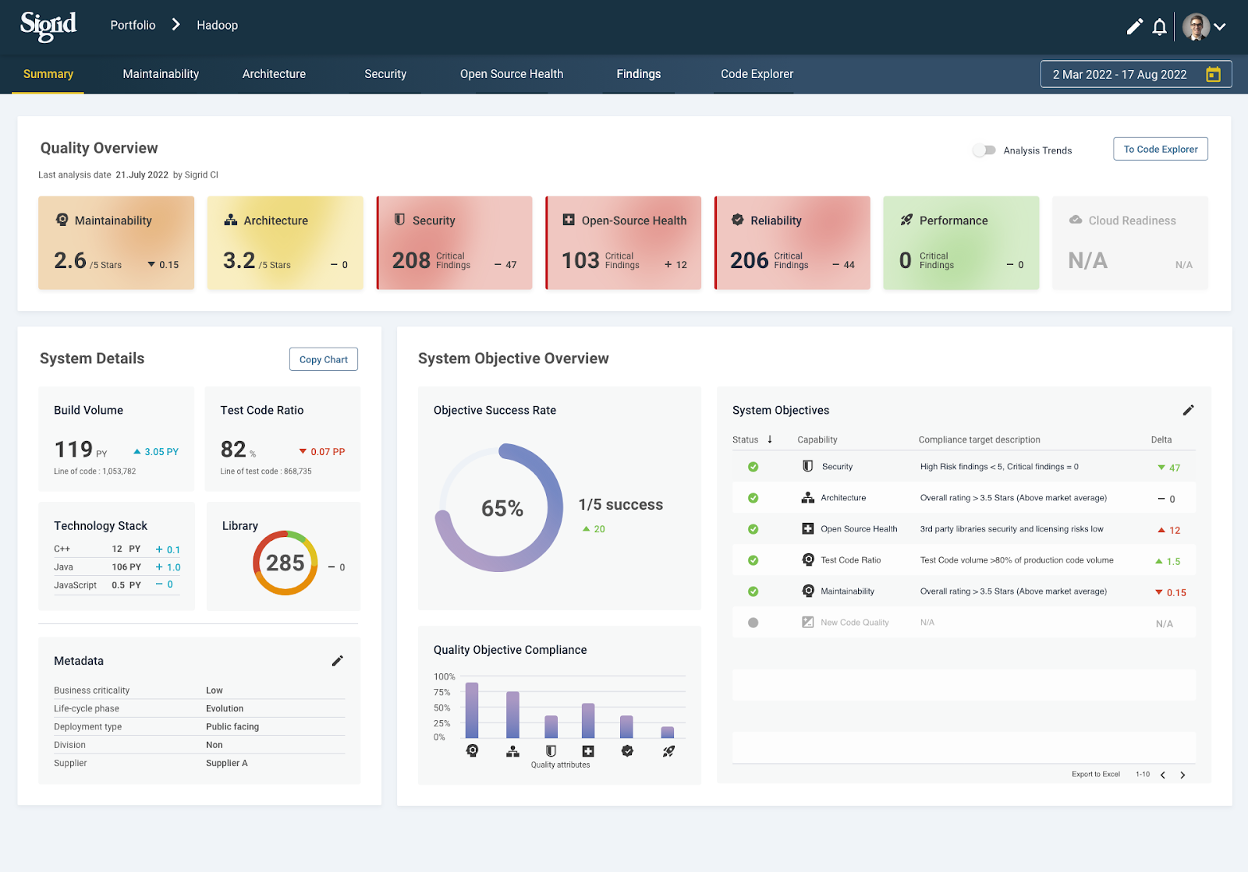
Figure 1 – The new dashboard showcases several distinct features under a single, unified view.
For this post, let’s assume each card on the page is powered by a dedicated service that performs the necessary calculations and aggregations. For the example mentioned, this means that seven distinct services need to be called to retrieve all the data for the dashboard.
Since the decision was to expose a single REST “gateway-style” endpoint call from the client, this means the following for performance when using a single thread of execution as described above:
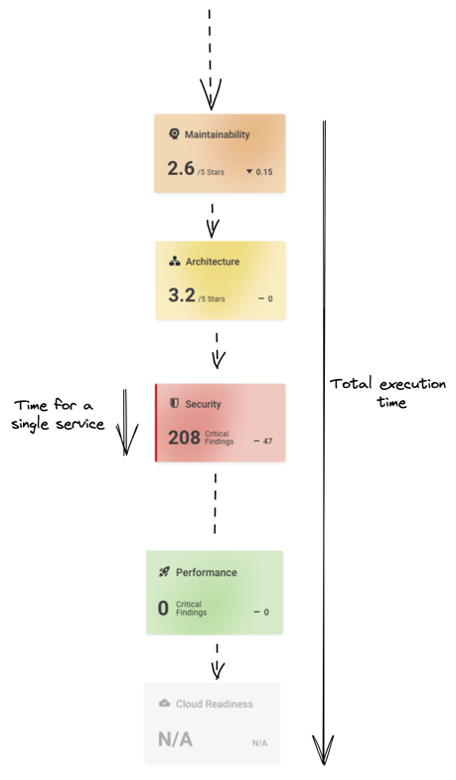
Figure 2 – Illustration of how the original version of the dashboard was performing its calculations.
As we can see in the figure above, in a single-threaded execution, the total time to complete all calculations is the sum of the time each service takes to perform its calculation. For example, if there are 7 services that each take 2 seconds to calculate, the total time to power the dashboard would be 14 seconds. However, there are ways to improve this time.
Strategy design pattern and independent calculations – critical ingredients for the solution
The critical aspect that steered us towards an answer to this performance issue was the fact that for each of the above calculations, the data required by each calculation was independent of each other. Thanks to this structure of our data, the Strategy Design pattern was a great fit, and by using it we took advantage of the following couple of benefits:
- Structuring the code in a way that lends itself to further improvements – we can add new functionality by adding new code rather than modifying existing one, which makes the process less error-prone and more efficient;
- Since each calculation is independent of the others, this means that the work can be parallelized and the execution can be spanned across multiple threads running in parallel.
Using the strategy design pattern
The Strategy pattern suggests that you take a class that does something specific in a lot of different ways and extract all of these algorithms into separate classes called strategies.
The idea is that these strategies are independent of each other and that there is a top-level context, provided by an “umbrella” class, that is responsible for triggering the execution of the right strategy at runtime.
This encapsulation is done through an interface implemented by the distinct classes, which then performs its calculations internally according to the specific strategy it implements.
In our particular case, the abstraction chosen to encode our strategies was a so-called “FeatureCalculation” interface with a method, performCalculations(FeatureType) which then was realized in concrete classes.
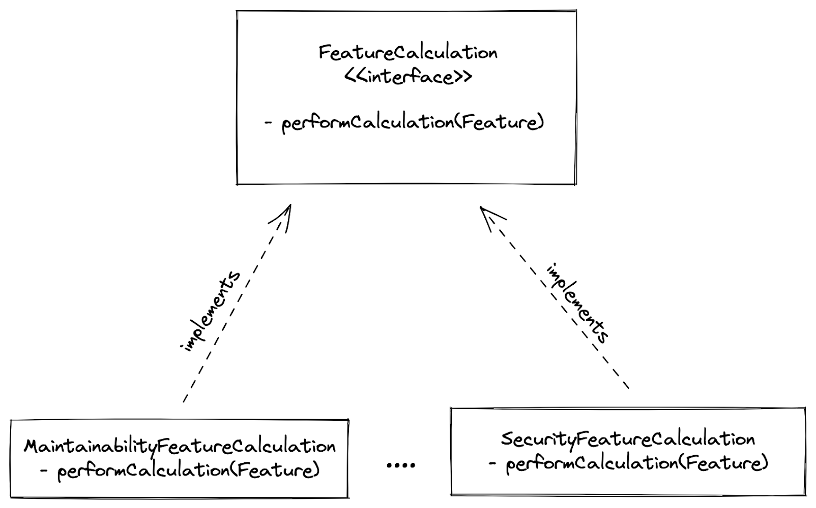
Figure 3 – Each specific feature has its implementation of a generic calculation mechanism
This nicely encapsulates the domain knowledge that each feature’s specific calculations are independent of each other. As a bonus, it enables us to expand the dashboard with new features in a very natural and easy manner.
This was the first part of the design that enabled the improvement we will discuss next, namely, performing each individual calculation in its thread.
Running the calculations in parallel – leveraging asynchronous workloads with Spring Boot
In Spring Boot, one way to implement the strategy pattern is to have a Map declared at the “umbrella” class level, which maps a particular “context” key to the interface that encapsulates the strategies.
At runtime, all beans implementing that interface are automatically autowired to fulfill their role.
The advantage of leveraging design patterns is that the code becomes structured so that extensions or future enhancements to it are easy to implement, one such extension being changing its technical characteristics, as we’ll explain below.
In our case, the future enhancement was that the calculations for each of these services would be performed asynchronously, so we would take advantage of the processing power that was available to us server-side and exchange it for much better performance – essentially, the total run time would go down from being the <sum of each calculation> to <runtime of the single, longest calculation>.
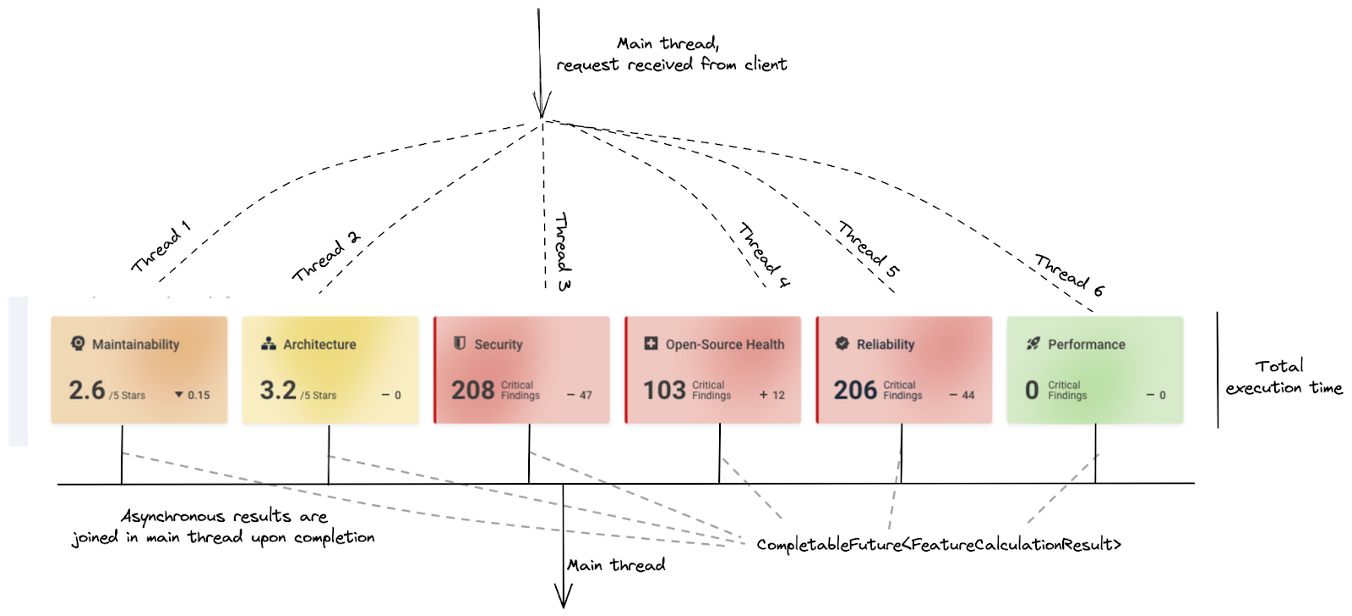
Figure 4 – How asynchronous execution improves performance for our dashboard
The idea is that instead of synchronously calling each of the `performCalculation(Feature)` methods in the main thread, which would result in a very expensive and long computation, we can offload work to distinct worker threads that can be run simultaneously, and then merge the results once they are all completed in the main thread, making the total run time that of the longest running job plus the cost of actually merging the results.
Spring Boot offers support for asynchronous programming by allowing a specific configuration class, annotated with the `@EnableAsync` annotation that implements the `AsyncConfigurer` interface, to be programmatically defined.
Our development team was already using it in a simpler form for another use case, but we decided to explore it further and see if we could use any of the additional methods available to cater to our new needs.
The `AsyncConfigurer` interface requires the configuration class to implement the method: `getAsyncExecutor()` which returns an Executor, which is essentially, in Java terms, a hand-crafted ThreadPool executor configured with the desired parameters for your particular use case. This was where delving deeper into the framework capabilities paid off, and we could accomplish our goal of running our different “FeatureCalculation” services in parallel.
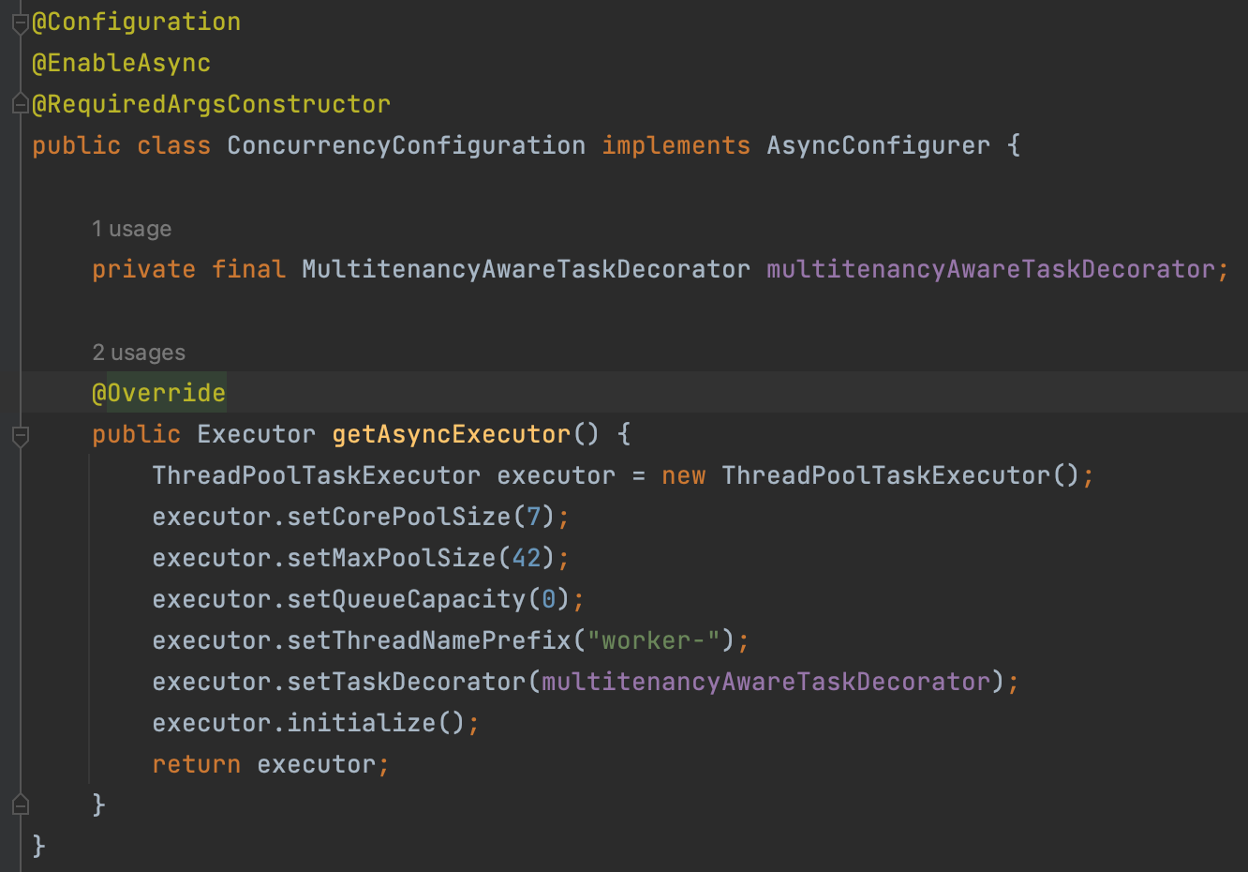
Figure 5 – Configuration for enabling asynchronous execution on our Spring Boot application
The most notable aspect we will highlight here is the setting of a task decorator, here realized by a MultitenancyAwareTaskDecorator.
At a high level, setting this task decorator allows for setting the execution context around the task’s invocation, or providing some monitoring/statistics for task execution.
As a side note, this is actually the realization within the Spring Boot framework of another design pattern, appropriately called Decorator.
The idea behind the decorator design pattern is to add new behavior to an existing object without modifying its structure. This is achieved by creating a decorator class that wraps the original object and adds new behaviors to the decorator.
In the example above, the task decorator achieves this by “decorating” the task to be executed with the decorator we provide to it. In our case, the decorator is responsible for making our tasks “multitenancy aware”.
For Sigrid’s use case, where we work with a multi-tenant setup where all the customer data is in the same database, this decorator provided exactly the right tool for the job: we wanted to be able to set, for the different threads, the execution context, which ensures the scope of data visible and accessible is only the one required and defined by the execution context.
From a code perspective, this task decorator is a Spring-annotated component that implements a functional interface, TaskDecorator, that requires overriding the `Runnable decorate(@NotNull Runnable runnable) `.
This receives the parent thread as a Runnable argument and the idea is that we will return a new Runnable, which in this case will be the child thread that can then be contextually enriched with any information needed from the parent thread, allowing the child thread to run with context which was the key for our case.
Finally, to get the complete picture, there are only two more additional details that need to be mentioned to ensure that the setup works as expected: the methods we want to execute within the child threads must be public, so that they can be discovered by Spring via the annotations, and they must, mandatorily, return a CompletableFuture<> wrapper type, indicating that since the methods will be executed in child threads, they will be completed in the future, and their results will be aggregated in the main thread. An example of the signature for computing the maintainability piece would be:
@Async
@Transactional(propagation = MANDATORY)
@LogTiming(parameterNames = {“featureType”})
public CompletableFuture<OverviewTilesResponseDTO> performCalculationForLicense(FeatureType f) {
….
}
Here we add the Async annotation on top, and we see that the method returns a CompletableFuture wrapper type.
With these aspects in place correctly, the method will be executed in a separate thread, managed by the thread pool executor we saw earlier.
Conclusion
With this detailed view into how we have designed our new dashboard, we realized how important it is to look into your business domain to see where “seams” are that enable data separation, and then, together with using battle-tested design patterns, we were able to easily tailor a solution to our needs to implement functionality that is tenant-dependent in an asynchronous way, giving us much more maintainable code that is easier to extend and whose performance is much easier to improve.
Thanks to my colleague Mircea Cadariu for reviewing this blog post and providing several suggestions for improving content and clarity, and thanks to my colleague, Fabian Lockhorst, for all the development work done together to see this implementation to its completion.