This is the last installment of the blog post series about legacy modernization at SIG. In the previous post, we looked at the decommissioning from a technical perspective, the reasons we had to do the decommissioning, and how we were using Crowd at SIG.
In the second and last part of this blog series, we look at the new data model that was introduced, and how data was effectively migrated between systems. Finally, we wrap up with a look at the performance and landscape benefits this effort has brought.
New Data Model and Storing authorization data
When designing a new data model from scratch, especially in the case of decommissioning a legacy system, in addition to considering potential future model changes, it’s perhaps even more important to consider the minimum viable data model that can support the necessary existing use cases without over-compromising future flexibility.
In other words, try to encode in the data model only the necessary and sufficient data tables and constraints that will enable it to work today, and that make the model easier to change in the future, minimizing the number of moving parts to complicate potential future data migrations.
Going back to the previous blog post: managing authorizations involves two data model entities and a mapping table to link them together: there are users, there are portfolios, and systems (which can be seen as one entity: user groups) and then there is the relationship between these entities. In a UML-style diagram, in a very simplified way, we have the following model:
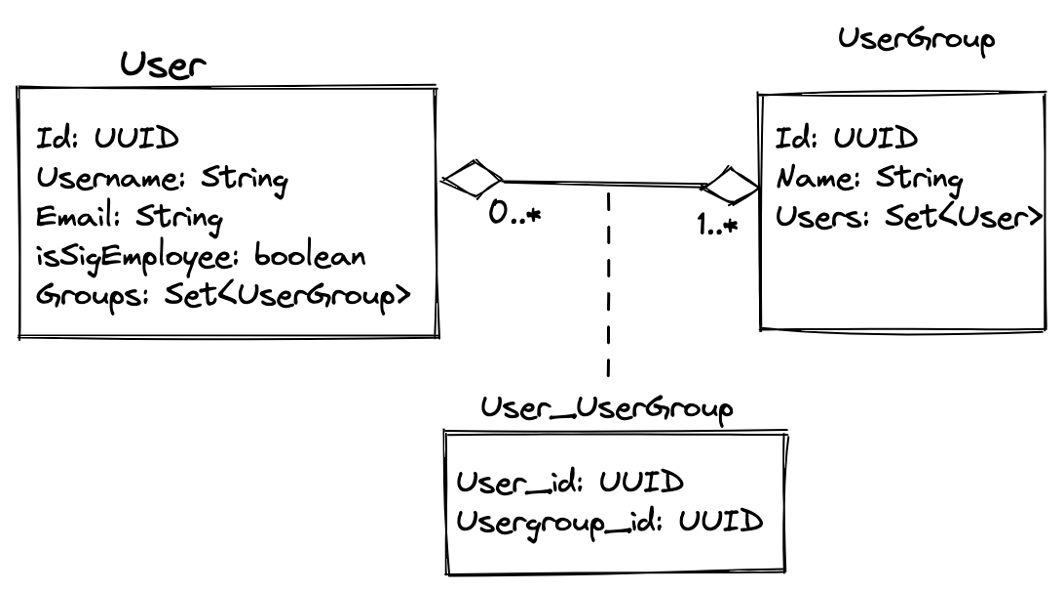
Figure 1 – Adopted data model to cater to the new system once Crowd is removed
As we can see above, the new data model is as simple as it needs to be to get the job done: mapping users to the collection of their authorized access portfolios and/or systems.
There are some crucial aspects that guarantee the full backward compatibility of this new data model with Crowd.
The relationship table User_Usergroup encodes the many-to-many nature of the relationship between users and groups along with the required constraints we would expect in a model of this nature: a user must always be in at least one group, and a group can have any range of users from 0 (think, a newly created group) to many.
The other very important aspect is that the group names for users would follow the conventions that were in place in Crowd.
This was the aspect that really allowed a “façade” between the two systems and allowed us to have both systems coexisting while everything continued to work as intended.
With this convention in place, when both systems were used side-by-side and requested at runtime when it was needed to make an authorization decision, we could simply merge the groups from both sources into a Java set, programmatically removing duplicates and ensuring that the clients would get their access as expected.
The next decision that followed was that we would leverage our existing AWS infrastructure and create a separate database in our existing RDS instance to manage these new authorizations under the new data model.
This was a no-brainer for us, especially since we already use RDS for managing our main application DB and already have experience with it, so it was natural to use it for this as well.
From a technical perspective, this meant that with this new change, Crowd could be completely out of the picture, both for the test setup we had in place and for the real production setup, which would amount to a new setup similar to the image below:
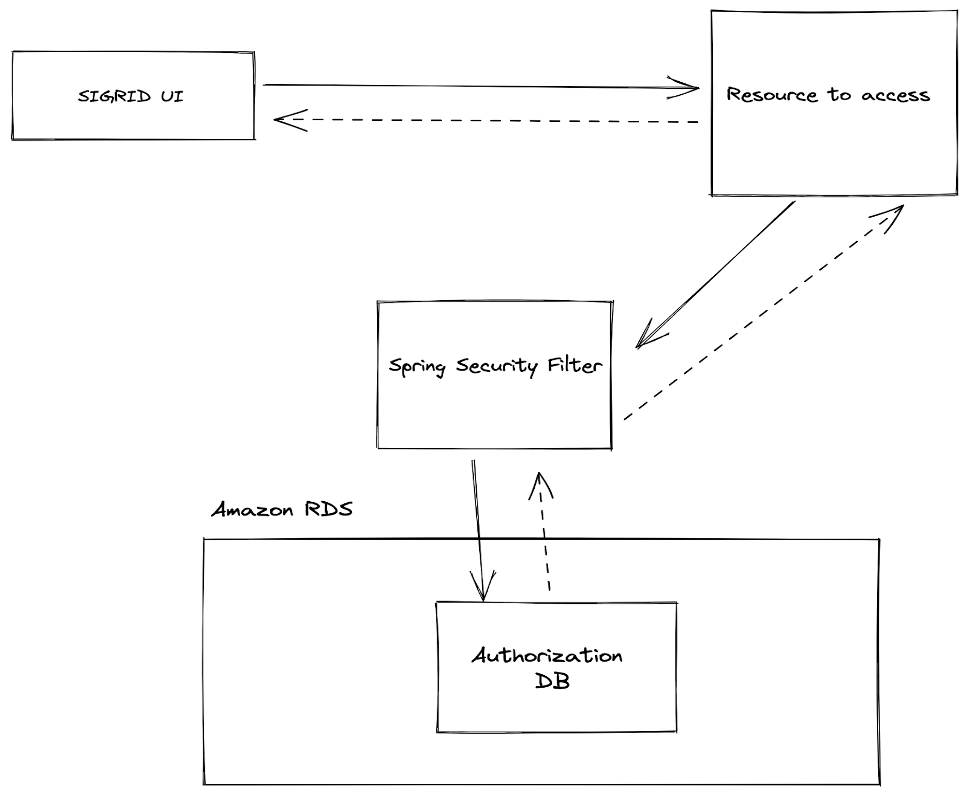
Figure 2 – New setup for managing Authorizations with Crowd out of the picture
The key point in the above setup is that now, with Crowd out of the picture, all authorizations are managed in a newly introduced RDS database which will be responsible for managing the authorizations for both SIG employees and customers.
This has the advantage of centralizing the responsibility within the scope of our infrastructure, making management, maintenance, and future changes easier.
The other very obvious benefit is the performance improvement across our landscape as a result of removing Crowd. We will dive into the specifics later on.
Data migration from Crowd to the newly introduced database
Now that the new infrastructure setup and data model are in place, the next step is to move the data from what we had in Crowd to the newly introduced data model and store it in the new database.
The idea is to combine several pieces of our landscape to achieve this:
- Connect to the Crowd API via a pre-existing Java Crowd Client implementation, living in our codebase as a standard Spring Boot component;
- Through this client, we retrieve the data from Crowd and convert it to fit our new data model;
- Once step 2 is done, by leveraging Hibernate and its entity representation of our DB tables, the data is “transferred” to the new Authorization DB. Note that for this step, during the actual migration process, an RDS-managed replica is used, i.e., a disposable copy of the real production database is used to ensure correctness and consistency before applying it for real.
The use of these replicas acts as an extra safety net before the real migration is performed;
After these three steps, a sanity check is applied when the current content of Crowd matches the content in the Authorization DB.
- After verifying the contents of both data sources and checking that everything is correct, the migration can be done for real. This means that data is retrieved from Crowd and converted to fit our new data model and then stored in our new DB.
This is done via a CLI SpringBoot application that runs on its own and exists only to migrate the Crowd data to the new data model.
Then, as detailed in part 1, once the data migration is complete, we apply the strangler architecture pattern to complete the migration process.
Improvements post-migration
After the migration was completed and Crowd was no longer used directly in our infrastructure, we used the nice observability capabilities of AWS X-Ray to verify the improvements our infrastructure has benefited from.
We can observe below in an X-Ray trace analysis how much impact Crowd had on our existing response times for some endpoints:

We can see how for this given request, the total time was 4.7 seconds, and we can see how a single call to Crowd took 4 seconds!
After removing Crowd, we have gained more control and flexibility over our authorization management, we have improved the performance of our SIGRID platform as a byproduct, and last but not least, we learned many valuable lessons about cross-team collaboration, expectation management, applying the right patterns for the task and considering the impact of our work at multiple levels in our landscape, from our consultants to our customers.
Conclusion
Implementing large-scale changes, such as decommissioning of Crowd at SIG, provides a unique opportunity to explore the limits of our platform and our engineering teams.
When availability is required and working with customer-facing features that have an impact, it becomes even more important to make trade-offs between high availability and data preservation.
We have learned that when our team is fully focused on a difficult problem like this, we are capable of delivering improved performance with little to no issues affecting customers.